
Scrape Table From Website Using Python Pandas
Pandas is used for extracting data from HTML tables with the read_html function. Read the article to learn about web scraping using Pandas.| ScrapeHero
Pandas is used for extracting data from HTML tables with the read_html function. Read the article to learn about web scraping using Pandas.| ScrapeHero

XPath (XML Path Language) is a syntax for defining parts of an XML document. We will explain the relevance of Xpaths in web scraping.| ScrapeHero

A concise XPath cheat sheet for web scraping that comes in handy for you to extract specific data from web pages.| ScrapeHero

This article explains how you can block specific resources in Playwright. The later section also gives an explanation of how to block requests in Chrome.| ScrapeHero

Importance of web scraping vs. web crawling in data extraction, various techniques and tools used, underlying benefits, and challenges.| ScrapeHero

Web scraping with BeautifulSoup allows you to access HTML elements conveniently. It will also support your preferred parser.| ScrapeHero

Selenium allows you to extract data from dynamic websites, making it great for web scraping hotel prices from Hotels.com.| ScrapeHero

Puppeteer is a node.js library which provides a powerful but simple API that allows you to control Google’s Chrome browser. In this tutorial post, we will show you how to use puppeteer to control chrome and build a web scraper to scrape details of hotel listings from booking.com| ScrapeHero

Dynamic websites generate HTML code at run time. You can use the Selenium library for scraping dynamic web pages with Python.| ScrapeHero

Create a Python scraper with Requests following this step-by-step web scraping guide, which covers all the essential basics.| ScrapeHero

Our web scraping services helps you extract data from websites without any technical hassle. Here is a list of data services ScrapeHero provides| ScrapeHero

Bypass anti-scraping by implementing effective strategies listed to navigate the websites without getting blocked for scraping data.| ScrapeHero
1. Installation¶| selenium-python.readthedocs.io

When scraping many pages from a website, using the same IP addresses will lead to getting blocked. A way to avoid this is by rotating proxies and IP addresses that can prevent your scrapers from being disrupted. In this tutorial, we will show you how to rotate proxies and IP addresses to prevent getting blocked while scraping.| ScrapeHero
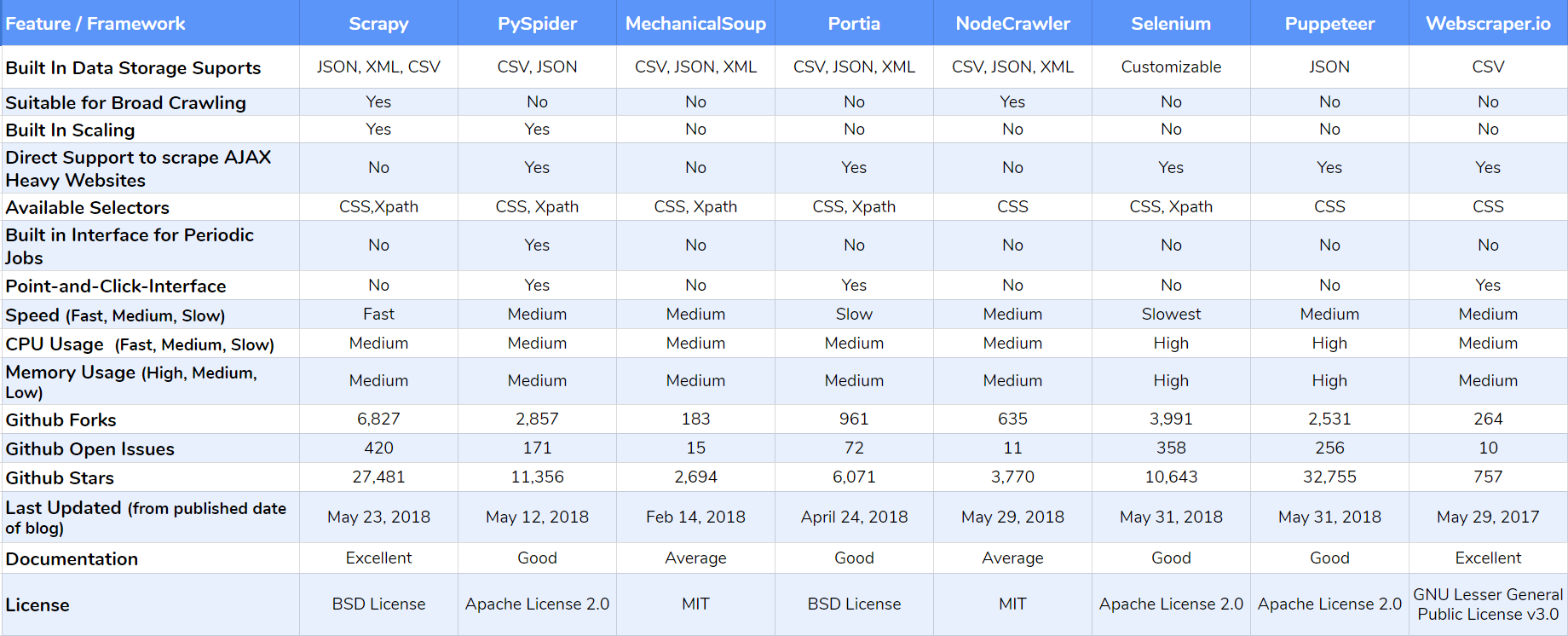
Using web scraping frameworks and tools are great ways to extract data from web pages. In this post, we will share with you the most popular open source frameworks for web scraping and tools to extract data for your web scraping projects in different programming languages like Python, JavaScript, browser-based, etc.| ScrapeHero

Learn how to scrape prices from Ebay.com in this Web Scraping tutorial using Python 3. This tutorial will show you how to extract product names and prices based on a particular brand available on Ebay. Scraping data from eBay.com at regular intervals can be useful to check the details of products and compare them with your competitor sites.| ScrapeHero

Source code: Lib/urllib/request.py The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirection...| Python documentation

The article lists 5 best open-source JavaScript web scraping tools in 2025, such as Puppeteer and Playwright, with their essential features and best use cases.| ScrapeHero

