A transparency and interpretability tech tree — AI Alignment Forum
Thanks to Chris Olah, Neel Nanda, Kate Woolverton, Richard Ngo, Buck Shlegeris, Daniel Kokotajlo, Kyle McDonell, Laria Reynolds, Eliezer Yudkowksy, M…| www.alignmentforum.org
Thanks to Chris Olah, Neel Nanda, Kate Woolverton, Richard Ngo, Buck Shlegeris, Daniel Kokotajlo, Kyle McDonell, Laria Reynolds, Eliezer Yudkowksy, M…| www.alignmentforum.org

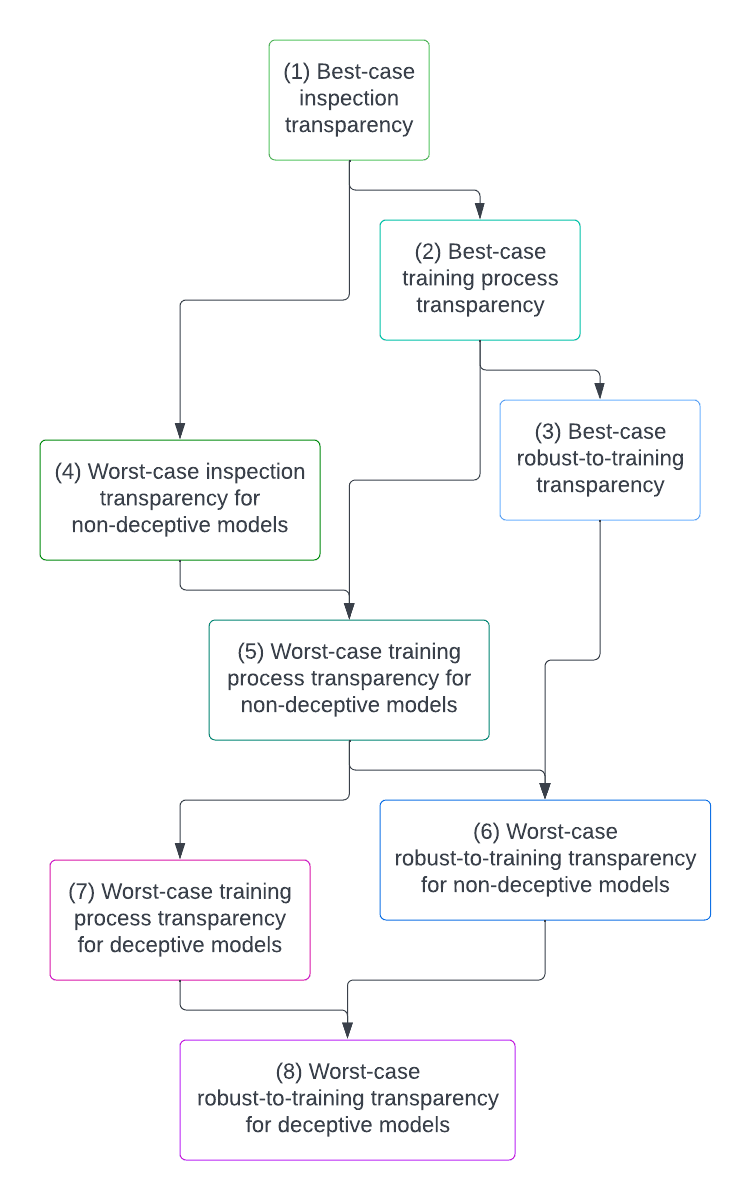
TL;DR: This document lays out the case for research on “model organisms of misalignment” – in vitro demonstrations of the kinds of failures that migh…| www.alignmentforum.org
