
Florence 2 - a Hugging Face Space by gokaygokay
Upload an image and select a task like captioning, object detection, or OCR. Get detailed text descriptions and visual annotations as results.| huggingface.co
Upload an image and select a task like captioning, object detection, or OCR. Get detailed text descriptions and visual annotations as results.| huggingface.co
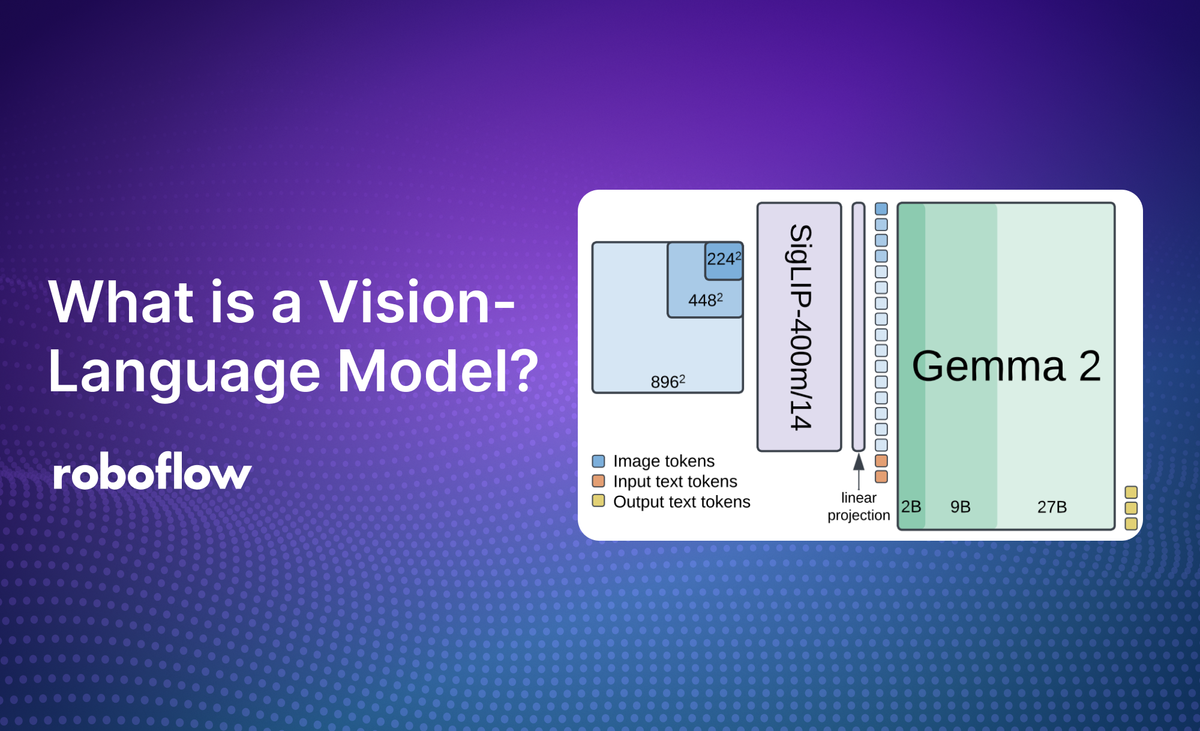
Learn what a VLM is and how to use VLMs in Roboflow Workflows to perform various vision tasks.| Roboflow Blog

Learn how Meta Research's new Segment Anything Model works to achieve high performance on image segmentation tasks.| Roboflow Blog

Learn how to use Florence-2 in Roboflow Workflows for zero-shot object detection, OCR, and more.| Roboflow Blog

The computer vision research community benchmarks new models and enhancements to existing models to test model performance. Benchmarking happens using standard datasets which can be used across models. With this approach, the efficacy of various models can be compared, in general, to show how one model is more or less| Roboflow Blog
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results ...| arXiv.org
