
How to Think about Large Language Models
Part IV of A Conceptual Guide to Transformers| benlevinstein.substack.com
We analyze the type of learned optimization that occurs when a learned model (such as a neural network) is itself an optimizer - a situation we refer to as mesa-optimization, a neologism we introduce in this paper. We believe that the possibility of mesa-optimization raises two important questions for the safety and transparency of advanced machine learning systems. First, under what circumstances will learned models be optimizers, including when they should not be? Second, when a learned mod...| arXiv.org
Part IV of A Conceptual Guide to Transformers| benlevinstein.substack.com

Part III of A Conceptual Guide to Transformers| benlevinstein.substack.com
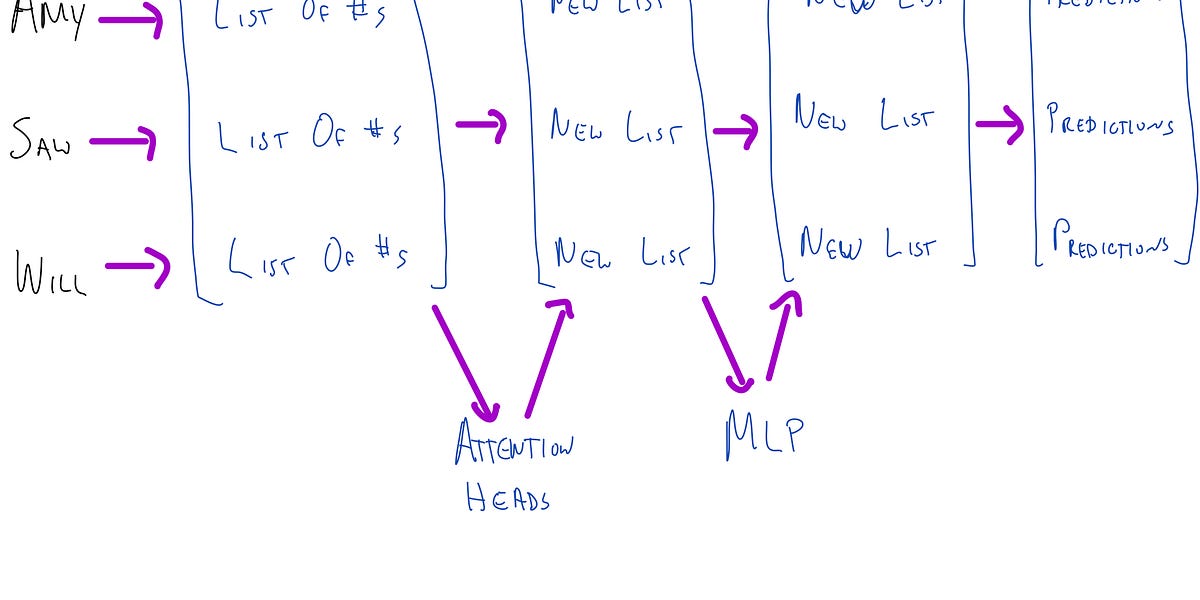
Architecture of the Transformer Model| benlevinstein.substack.com
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within a wide range. Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. These re...| arXiv.org

