
Lipschitz continuity - Wikipedia
Strong form of uniform continuity| en.wikipedia.org
[Updated on 2019-05-27: add the section on Lottery Ticket Hypothesis.] If you are like me, entering into the field of deep learning with experience in traditional machine learning, you may often ponder over this question: Since a typical deep neural network has so many parameters and training error can easily be perfect, it should surely suffer from substantial overfitting. How could it be ever generalized to out-of-sample data points?| lilianweng.github.io
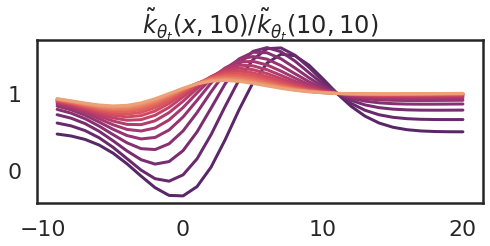
Neural tangent kernels are a useful tool for understanding neural network training and implicit regularization in gradient descent. But it's not the easiest concept to wrap your head around. The paper that I found to have been most useful for me to develop an understanding is this one:...| inFERENCe
