AI Capabilities Can Be Significantly Improved Without Expensive Retraining | Epoch AI
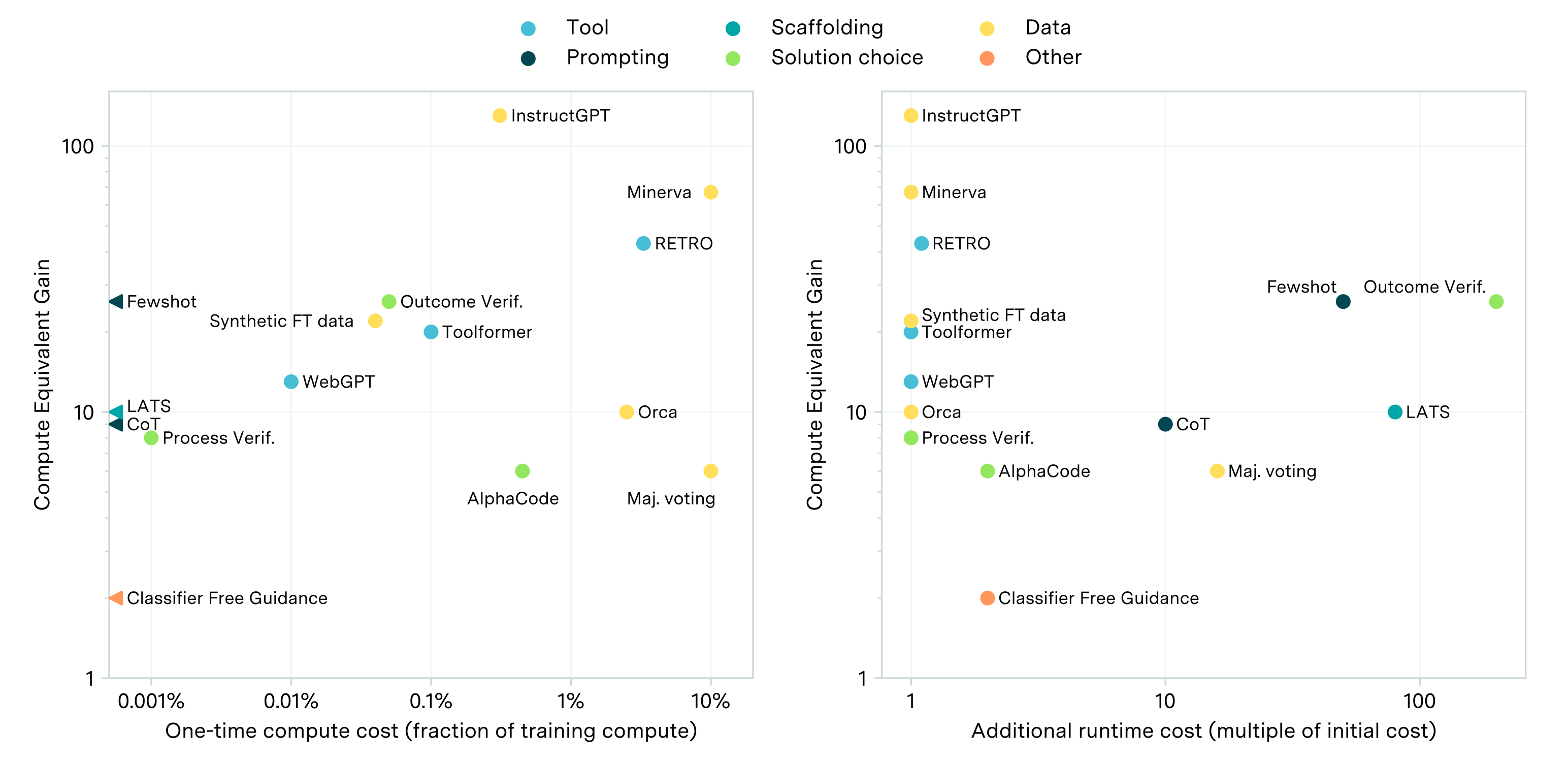
While scaling compute is key to improving LLMs, post-training enhancements can offer gains equivalent to 5-20x more compute at less than 1% of the cost.| Epoch AI
While scaling compute is key to improving LLMs, post-training enhancements can offer gains equivalent to 5-20x more compute at less than 1% of the cost.| Epoch AI
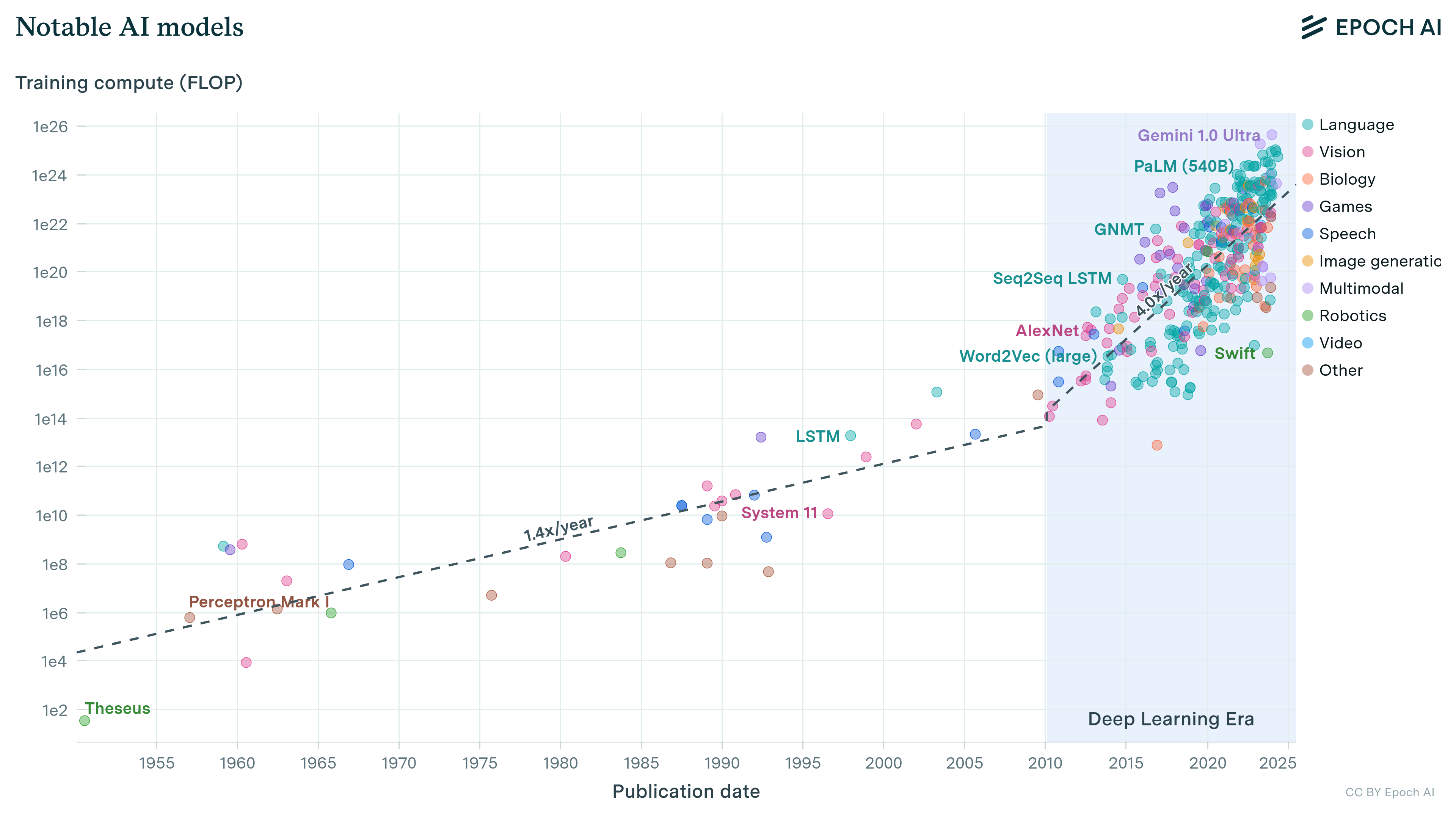
We’ve compiled a comprehensive dataset of the training compute of AI models, providing key insights into AI development.| Epoch AI
We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant. By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size ...| arXiv.org
