
What Is a URL? A Complete Guide to Website URLs
A URL is a detailed address that directs a web browser to an online resource’s exact location.| Semrush Blog
A URL is a detailed address that directs a web browser to an online resource’s exact location.| Semrush Blog

A robots.txt file tells search engine bots which pages they should and shouldn’t crawl. Learn more.| Semrush Blog

A canonical URL is the version of a webpage that search engines treat as “main“ when there are duplicates.| Semrush Blog

Crawlability refers to a search engine‘s ability to access web content and index it for ranking in search results.| Semrush Blog

Learn top internal linking strategies and get a free template to optimize your site‘s SEO and user experience.| Semrush Blog
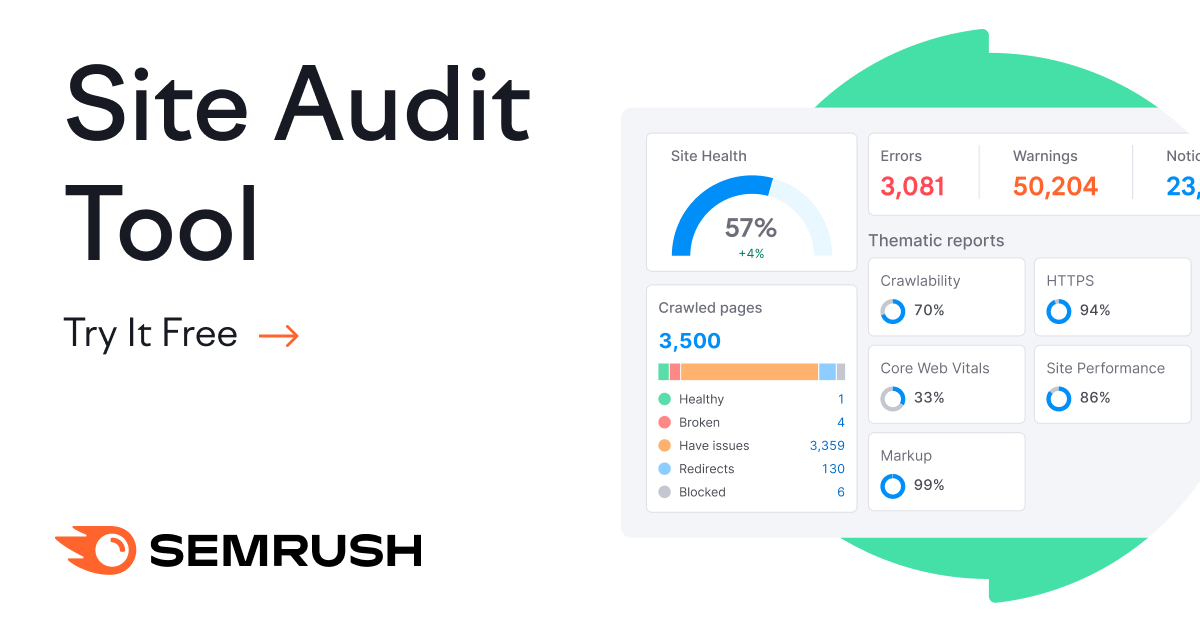
Free tool to run a website audit, check for SEO issues, and apply fixes that grow traffic and visibility.| Semrush
