
Scrape Table From Website Using Python Pandas
Pandas is used for extracting data from HTML tables with the read_html function. Read the article to learn about web scraping using Pandas.| ScrapeHero
Pandas is used for extracting data from HTML tables with the read_html function. Read the article to learn about web scraping using Pandas.| ScrapeHero

Web scraping with BeautifulSoup allows you to access HTML elements conveniently. It will also support your preferred parser.| ScrapeHero

Learn to do web scraping using Playwright in Python and JavaScript understanding the concept of headless browsers.| ScrapeHero

Puppeteer is a node.js library which provides a powerful but simple API that allows you to control Google’s Chrome browser. In this tutorial post, we will show you how to use puppeteer to control chrome and build a web scraper to scrape details of hotel listings from booking.com| ScrapeHero

Data extraction services help tap the vast data resources available online. This post is a data extraction services guide to helpwith your data management.| ScrapeHero

Dynamic websites generate HTML code at run time. You can use the Selenium library for scraping dynamic web pages with Python.| ScrapeHero
Using web scraping tools are a great alternative to extract data from web pages. In this post, we will share with you the most popular web scraping tools to extract data. With these automated scrapers you can scrape data without any programming skills and you can scrape data at a low cost.| ScrapeHero

We’re a global web crawling service for enterprises that delivers reliable and relevant data hassle-free. Join our 11,700+ customer base today.| ScrapeHero

Create a Python scraper with Requests following this step-by-step web scraping guide, which covers all the essential basics.| ScrapeHero

Bypass anti-scraping by implementing effective strategies listed to navigate the websites without getting blocked for scraping data.| ScrapeHero
Learn more about essential HTTP headers for web scraping. Understand their function and learn how they affect the web scraping process.| ScrapeHero

Explore different methods, such as HTTP fingerprinting and pattern detection, by which websites detect and block bots when web scraping.| ScrapeHero

Legal Information Disclaimer: ScrapeHero does NOT provide legal advice. Please consult your own legal counsel for advice.This page will provide updated| ScrapeHero

Hassle-free web scraping services scalable to millions of pages of data, optimized for enterprises. Join an expanding customer base of 10000+ including Fortune 50.| ScrapeHero

Download anything you see on the Internet into a spreadsheet with just a few clicks using our Crawlers and APIs. ScrapeHero Cloud is the easiest way to collect data from the Internet.| scrapehero-marketplace

When scraping many pages from a website, using the same IP addresses will lead to getting blocked. A way to avoid this is by rotating proxies and IP addresses that can prevent your scrapers from being disrupted. In this tutorial, we will show you how to rotate proxies and IP addresses to prevent getting blocked while scraping.| ScrapeHero
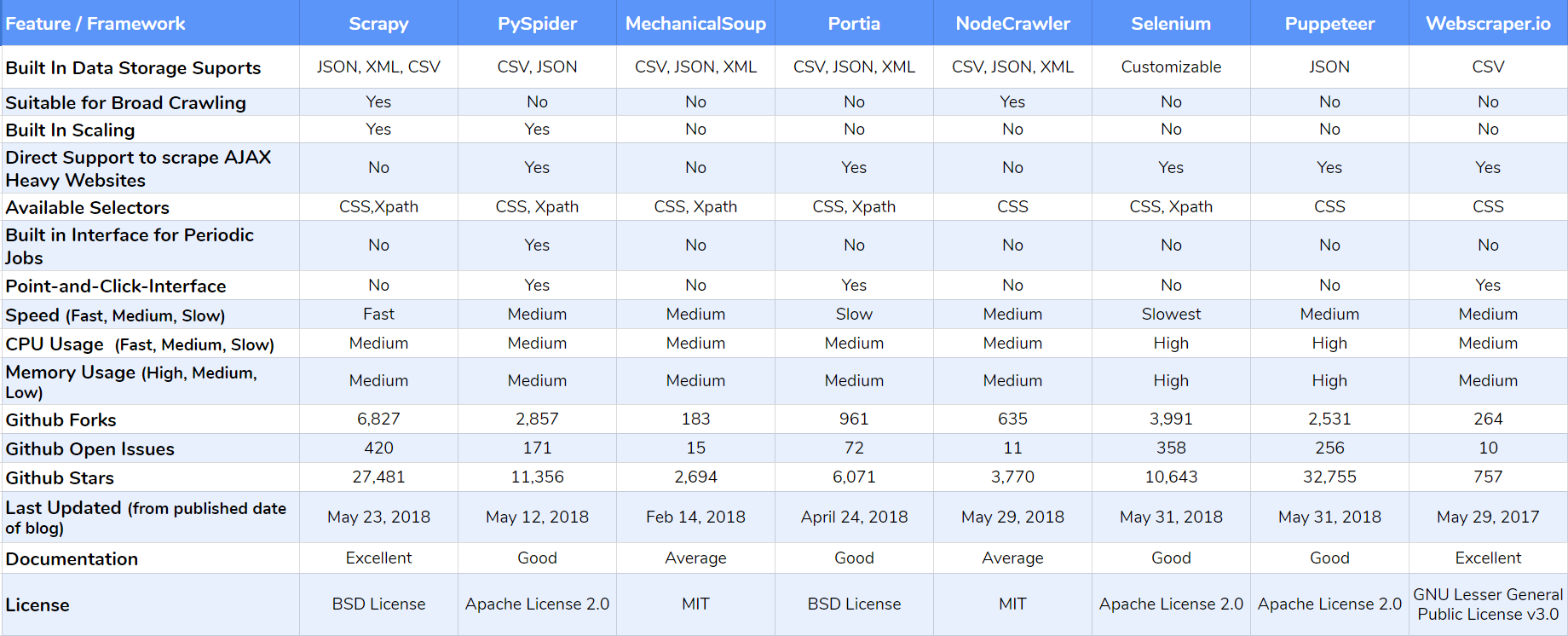
Using web scraping frameworks and tools are great ways to extract data from web pages. In this post, we will share with you the most popular open source frameworks for web scraping and tools to extract data for your web scraping projects in different programming languages like Python, JavaScript, browser-based, etc.| ScrapeHero

Googlebot is the generic name of the web crawler used by Google Search. Discover what Googlebot is, how it accesses your site, and how to block Googlebot.| Google for Developers
