
Fine-Tuning Llama 3.2 Vision
Fine-tuning Llama 3.2 Vision on a LaTeX2OCR dataset to predict raw LaTeX equations from images and creating a Gradio application.| DebuggerCafe
Fine-tuning Llama 3.2 Vision on a LaTeX2OCR dataset to predict raw LaTeX equations from images and creating a Gradio application.| DebuggerCafe

Llama 3.2 Vision model is a multimodal VLM from Meta belonging to the Llama 3 family that brings the capability to feed images to the model.| DebuggerCafe
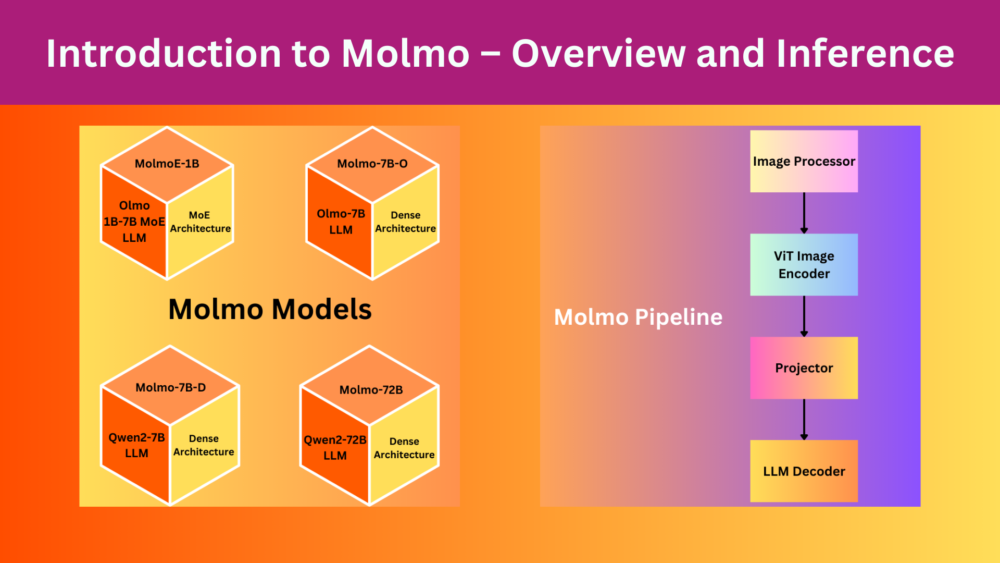
Molmo is a family of new VLMs trained using the PixMo group of datasets that can describe images and also point & count objects in image.| DebuggerCafe
Contact DebuggerCafe for Machine Learning, Deep Learning, and AI.| DebuggerCafe

Fine tuning Phi 1.5 using QLoRA on the Stanford Alpaca instruction tuning dataset with the Hugging Face Transformers library.| DebuggerCafe
