
TMA introduction | simons blog
Efficiently transferring data from global to shared memory and vice versa is often the bottleneck in CUDA applications. Therefore it's important we leverage ...| simons blog
Efficiently transferring data from global to shared memory and vice versa is often the bottleneck in CUDA applications. Therefore it's important we leverage ...| simons blog
In this blogpost we want to briefly describe how to archive SOTA performance for the task of reduction on a vector, i.e. our program should do the following:...| simons blog

The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will stud…| Colfax Research
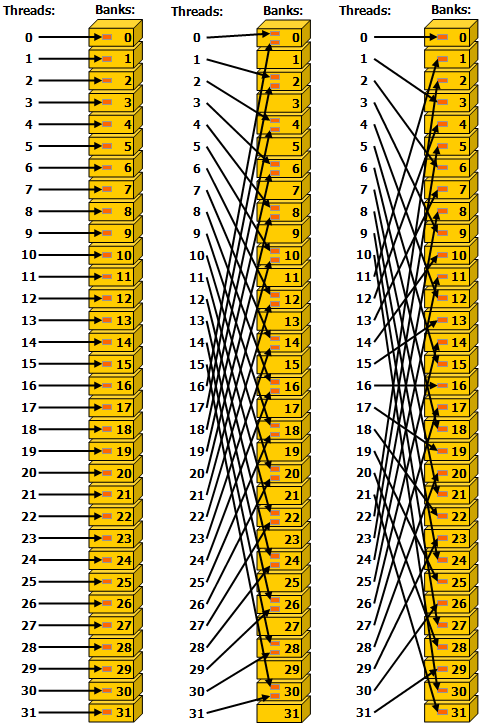
Avoiding CUDA Shared Memory Bank Conflicts| Lei Mao's Log Book
