Repetition and definition levels are a method of converting structural arrays into a set of buffers. The approach was made popular in Parquet and is one of the key ways Parquet, ORC, and Arrow differ. In this blog I will explain how they work by contrasting them with validity & offsets| LanceDB Blog
Record shredding is a classic method used to transpose rows of potentially nested data into a flattened tree of buffers that can be written to the file. A similar technique, cascaded encoding, has recently emerged, that converts those arrays into a flattened tree of compressed buffers. In this article we| LanceDB Blog
📄🌐The Lance Research Paper That's right, we finally published the Lance Research Paper on arXiv. Check out Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings. Read on arXiv 🔍Columnar File Readers in Depth: Compression and Transparency A new drop in the Columnar| LanceDB Blog
Conventional wisdom states that compression and random access do not go well together. However, there are many ways you can compress data, and some of them support random access better than others. Figuring out which compression we can use, and when, and why, has been an interesting challenge. As we've| LanceDB Blog
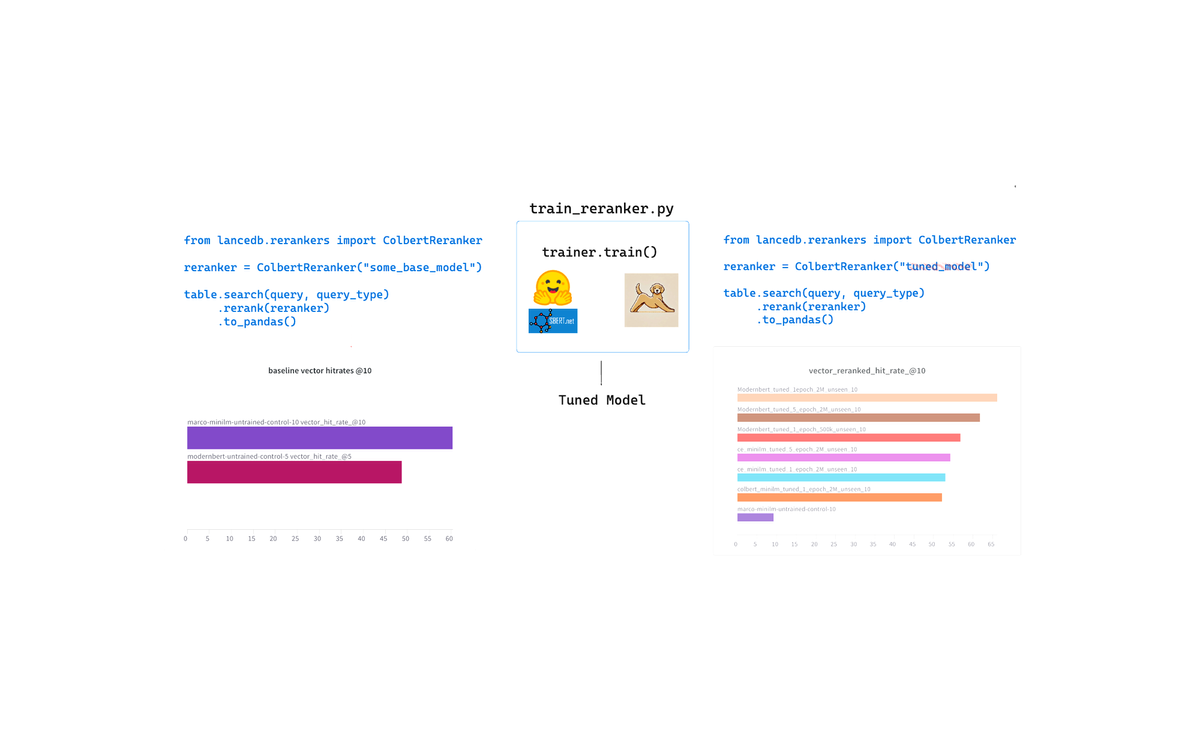
This is a follow up to the following report that deals with improving retrievers by training and fine-tuning reranker models A Practical Guide to Training Custom Rerankers A report on reranking, training, & fine-tuning rerankers for retrieval This report offers practical insights for improving a retriever by reranking results. We&| LanceDB Blog
As Continue offers user-controlled IDE extensions, most of the codebase is written in Typescript, and the data is stored locally in the ~/.continue folder. The tooling choices are made such that there are no separate processes required to handle database operations. Continue's codebase retrieval features are powered by| LanceDB Blog
A report on reranking, training, & fine-tuning rerankers for retrieval This report offers practical insights for improving a retriever by reranking results. We'll tackle the important questions, like: When should you implement a reranker? Should you opt for a pre-trained solution, fine-tune an existing model, or build one from scratch? The| LanceDB Blog
As the scale of data continues to grow, open-source table formats have become essential for efficient data lake management. Apache Iceberg has emerged as a leader in this space, while new formats like Lance are introducing optimizations for specific workloads. In this post, we’ll explore how Iceberg and| LanceDB Blog
☁️ LanceDB Cloud Public Beta The wait is over! LanceDB Cloud is now in Public Beta! No more wait list; just sign-up, get an API key, and start building AI with LanceDB Cloud - Serverless Retrieval for Multimodal AI! Try LanceDB Cloud (Public Beta) Now --- Good Reads 👀Lance| LanceDB Blog
AnythingLLM chose LanceDB as their vector database backbone to create a frictionless experience for developers and end-users alike. By leveraging LanceDB's serverless, setup-free architecture, the AnythingLLM team slashed engineering time previously spent on troubleshooting infrastructure issues and redirected it toward building innovative features. The result? An application that| LanceDB Blog
Almost a year ago I announced we were going to be embarking on a journey to build a new 2.0 version of our file format. Several months later, we released a beta, and last fall it became our default file format. Overall, I've been super pleased with| LanceDB Blog
💡This is a case study contributed by the Second Dinner team and the LanceDB team. Second Dinner teamed up with LanceDB Cloud’s serverless architecture to turbocharge their game development workflow. Overnight, system designers went from waiting months to spinning up prototypes in hours, slashing endless cross-team coordination. QA engineers,| LanceDB Blog