Predictive models trained on large datasets with sophisticated machine learning (ML) algorithms are widely used throughout industry and academia. Models trained with differentially private ML algorithms provide users with a strong, mathematically rigorous guarantee that details about their personal data will not be revealed by the model or its predictions.| research.google
Posted by Krishna Giri Narra, Software Engineer, Google, and Chiyuan Zhang, Research Scientist, Google Research Ad technology providers widely use ...| research.google
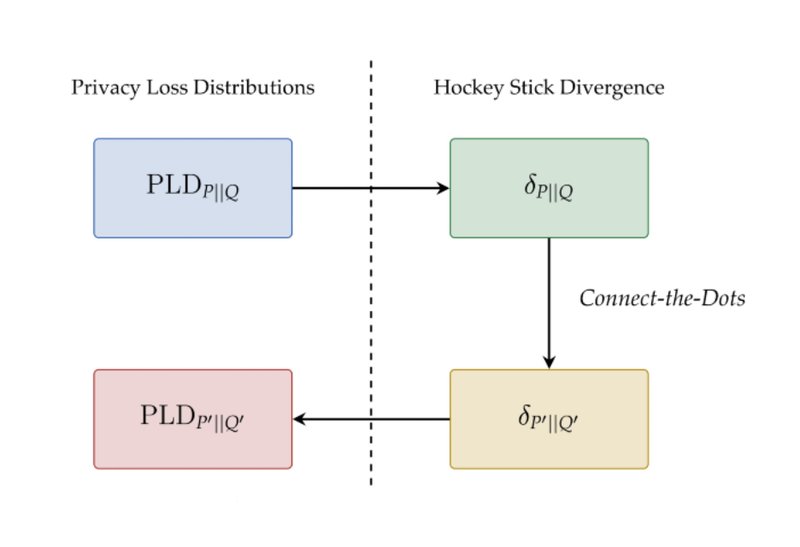
Posted by Pritish Kamath and Pasin Manurangsi, Research Scientists, Google Research Differential privacy (DP) is an approach that enables data anal...| research.google
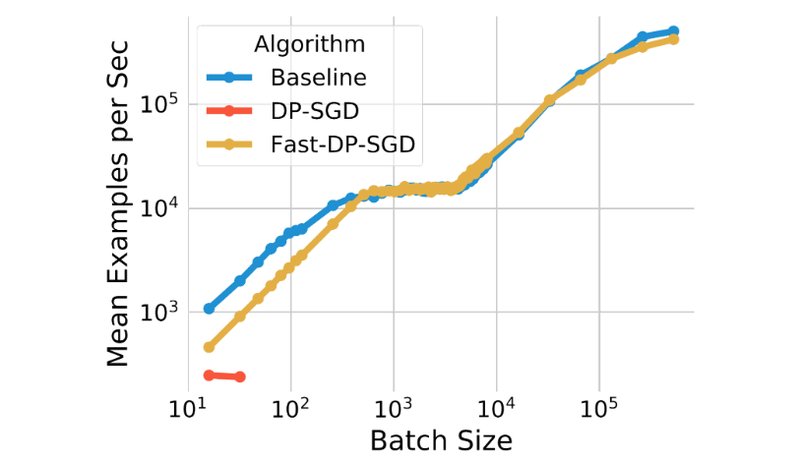
In today's world, machine learning (ML) models are becoming more ubiquitous. While they provide great utility, such models may sometimes accidentally remember sensitive information from their training data. Differential privacy (DP) offers a rigorous mathematical framework to protect user privacy by injecting "noise" during the model training procedure, making it harder for the model to remember information unique to individual data points. It is desirable to have techniques that provide the ...| research.google
We investigate practical and scalable algorithms for training large language models (LLMs) with user-level differential privacy (DP) in order to provably safeguard all the examples contributed by each user. We study two variants of DP-SGD with: (1) example-level sampling (ELS) and per-example gradient clipping, and (2) user-level sampling (ULS) and per-user gradient clipping. We derive a novel user-level DP accountant that allows us to compute provably tight privacy guarantees for ELS. Using ...| arXiv.org
We introduce Dataset Grouper, a library to create large-scale group-structured (e.g., federated) datasets, enabling federated learning simulation at the scale of foundation models. This library facilitates the creation of group-structured versions of existing datasets based on user-specified partitions and directly leads to a variety of useful heterogeneous datasets that can be plugged into existing software frameworks. Dataset Grouper offers three key advantages. First, it scales to settings...| arXiv.org
We demonstrate that it is possible to train large recurrent language models with user-level differential privacy guarantees with only a negligible cost in predictive accuracy. Our work builds on recent advances in the training of deep networks on user-partitioned data and privacy accounting for stochastic gradient descent. In particular, we add user-level privacy protection to the federated averaging algorithm, which makes "large step" updates from user-level data. Our work demonstrates that ...| arXiv.org
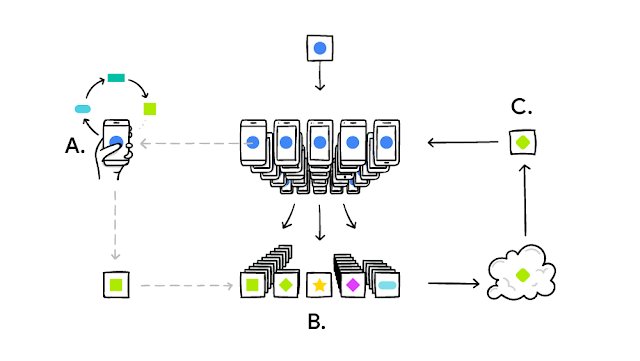
Posted by Brendan McMahan and Daniel Ramage, Research ScientistsStandard machine learning approaches require centralizing the training data on one ...| research.google