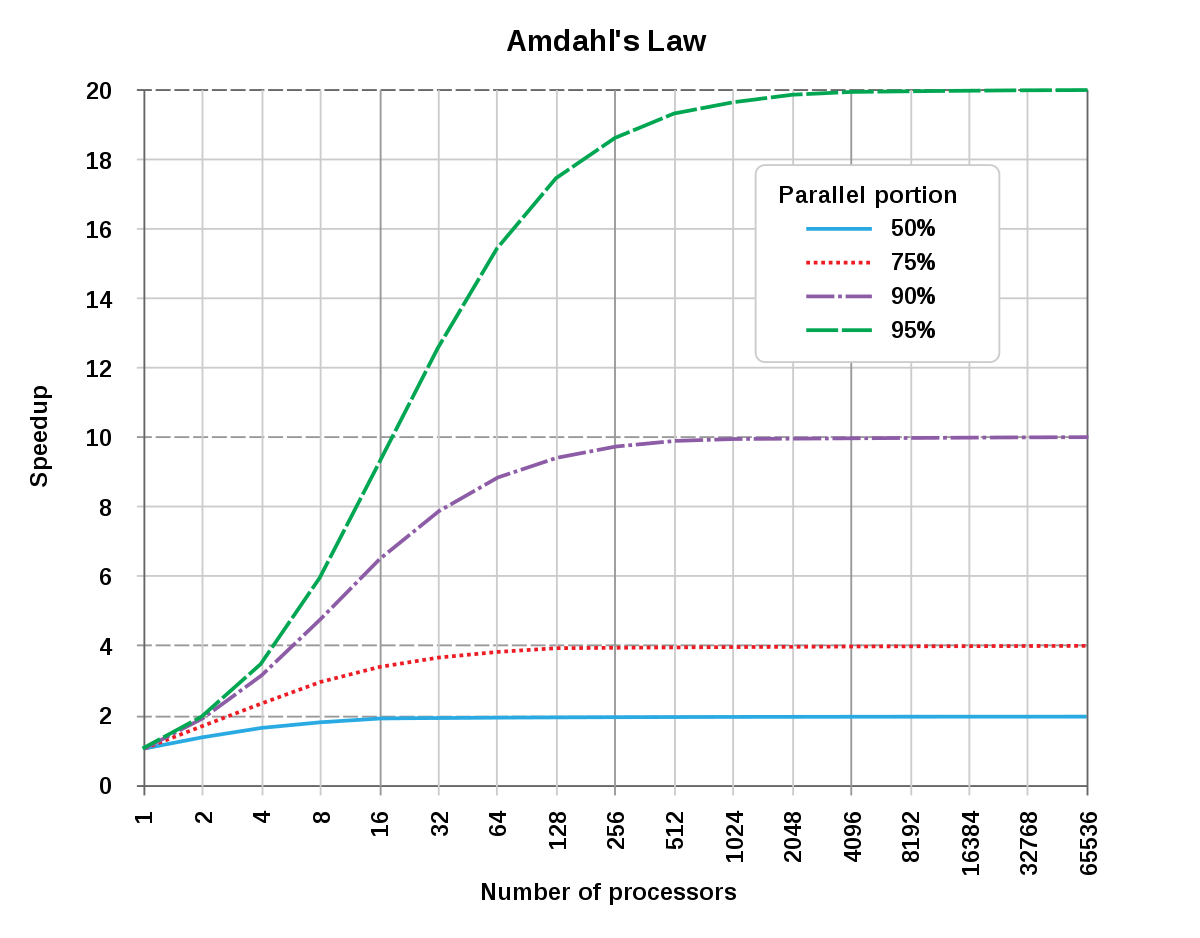
Amdahl's law - Wikipedia
Formula in computer architecture| en.wikipedia.org
This guide has a set of example configurations for content clusters using flat or grouped data distribution.| docs.vespa.ai
An attribute is a schema keyword,| docs.vespa.ai
The nativeRank text match score is a reasonably good text| docs.vespa.ai
A document summary is the information that is shown for each document in a query result.| docs.vespa.ai
content| docs.vespa.ai
Proton is Vespa's search core and runs on each content node as the vespa-proton-bin process.| docs.vespa.ai
The distribution algorithm decides what nodes should be responsible for a given bucket.| docs.vespa.ai
Vespa offers configurable data redundancy with eventual consistency across replicas.| docs.vespa.ai
Vespa clusters can be grown and shrunk while serving queries and writes.| docs.vespa.ai
expand all| docs.vespa.ai
expand all| docs.vespa.ai
This document explains the common concepts necessary to develop all types of Container components.| docs.vespa.ai
Theorem in queueing theory| en.wikipedia.org
add| docs.vespa.ai
Vespa ranks documents retrieved by a query by performing computations or inference that produces a score for each document. | docs.vespa.ai
Use the Vespa Query API to query, rank and organize data. Example:| docs.vespa.ai
This document describes how to tune certain features of an application for high query serving performance,| docs.vespa.ai
expand all| docs.vespa.ai
Vespa allows expressing multi-phased retrieval and ranking of documents. The retrieval phase is done close to the data in the content nodes,| docs.vespa.ai
For an introduction to nearest neighbor search, see nearest neighbor search documentation, | docs.vespa.ai
