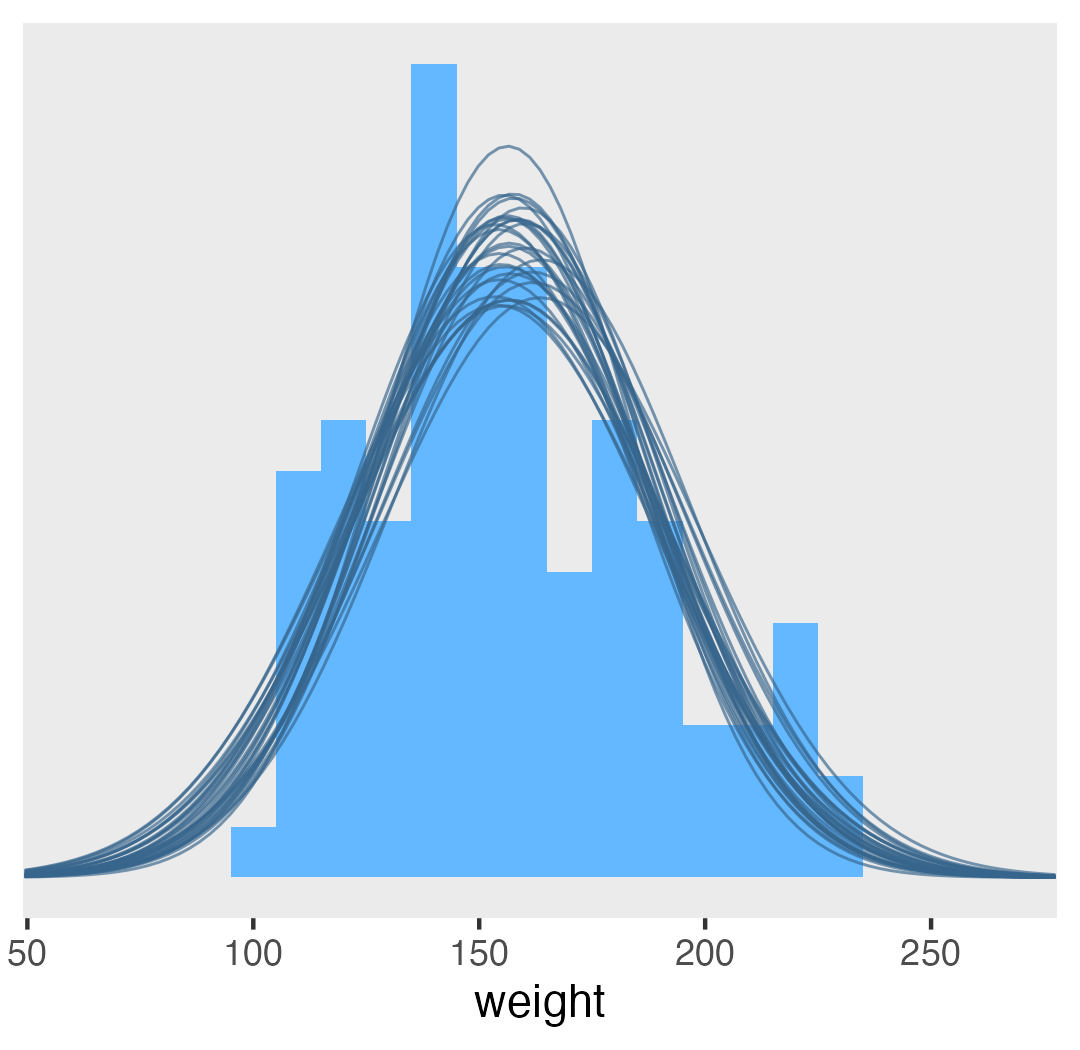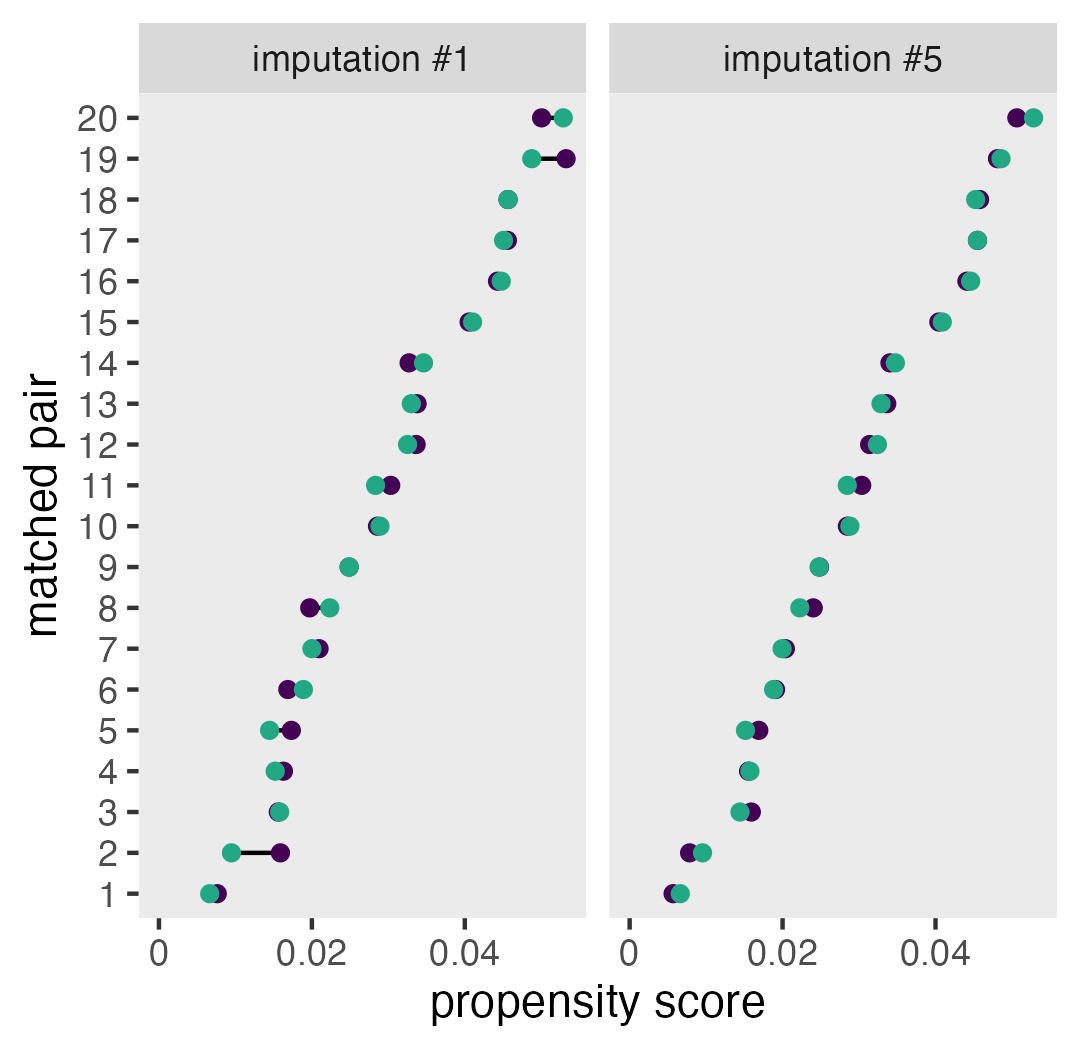
I'm finally dipping my does into causal inference for quasi-experiments, and my first use case has missing data. In this post we practice propensity score matching with multiply-imputed data sets, and how to compute the average treatment effect for the treated (ATT) with g-computation.| A. Solomon Kurz
Sometimes in the methodological literature, models for continuous outcomes are presumed to use the Gaussian likelihood. In the sixth post of this series, we saw the gamma likelihood is a great alternative when your continuous data are restricted to positive values, such as in reaction times and bodyweight. In this ninth post, we practice making causal inferences with the beta likelihood for continuous data restricted within the range of \((0, 1)\).| A. Solomon Kurz
So far in this series, we have used the posttreatment scores as the dependent variables in our analyses. However, it’s not uncommon for researchers to frame their questions in terms of change from baseline with a change-score (aka gain score) analysis. The goal of this post is to investigate whether and when we can use change scores or change from baseline to make causal inferences. Spoiler: Yes, sometimes we can (with caveats).| A. Solomon Kurz
We social scientists love collecting ordinal data, such as those from questionnaires using Likert-type items.1 Sometimes we’re lazy and analyze these data as if they were continuous, but we all know they’re not, and the evidence suggests things can go terribly horribly wrong when you do ( Liddell & Kruschke, 2018). Happily, our friends the statisticians and quantitative methodologists have built up a rich analytic framework for ordinal data (see Bürkner & Vuorre, 2019).| A. Solomon Kurz
So far the difficulties we have seen with covaraites, causal inference, and the GLM have all been restricted to discrete models (e.g., binomial, Poisson, negative binomial). In this sixth post of the series, we’ll see this issue can extend to models for continuous data, too. As it turns out, it may have less to do with the likelihood function, and more to do with the choice of link function. To highlight the point, we’ll compare Gaussian and gamma models, with both the identity and log li...| A. Solomon Kurz
In the third post in this series, we extended out counterfactual causal-inference framework to binary outcome data. We saw how logistic regression complicated the approach, particularly when using baseline covariates. In this post, we’ll practice causal inference with unbounded count data, using the Poisson and negative-binomial likelihoods. We need data We’ll be working with a subset of the epilepsy data from the brms package. Based on the brms documentation (execute ?| A. Solomon Kurz
In the first two posts of this series, we relied on ordinary least squares (OLS). In the third post, we expanded to maximum likelihood for a couple logistic regression models. In all cases, we approached inference from a frequentist perspective. In this fourth post, we’re finally ready to make causal inferences as Bayesians. We’ll do so by refitting the Gaussian and binomial models from the previous posts with the Bayesian brms package ( Bürkner, 2017, 2018, 2022), and show how to comput...| A. Solomon Kurz
So far in this series, we’ve been been using ordinary least squares (OLS) to analyze and make causal inferences from our experimental data. Though OLS is an applied statistics workhorse and performs admirably in some cases, there are many contexts in which it’s just not appropriate. In medical trials, for example, many of the outcome variables are binary. Some typical examples are whether a participant still has the disease (coded 1) or not (coded 0), or whether a participant has died (co...| A. Solomon Kurz