
Get to know the Google Pixel Watch | Track sleep and fitness hands-free
Stay connected & healthy with the Pixel Watch. Text, navigate, pay, stay safe, and track your well-being, all hands-free.| Google Store
Stay connected & healthy with the Pixel Watch. Text, navigate, pay, stay safe, and track your well-being, all hands-free.| Google Store
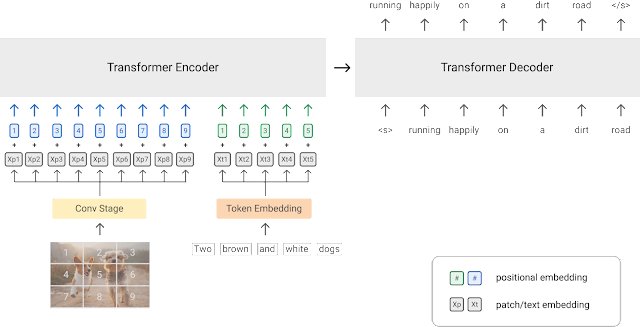
Posted by Zirui Wang, Student Researcher and Yuan Cao, Research Scientist, Google Research, Brain Team Vision-language modeling grounds language un...| research.google

Wearable devices that measure physiological and behavioral signals have become commonplace. There is growing evidence that these devices can have a meaningful impact promoting healthy behaviors, detecting diseases, and improving the design and implementation of treatments. These devices generate vast amounts of continuous, longitudinal, and multimodal data. However, raw data from signals like electrodermal activity or accelerometer values are difficult for consumers and experts to interpret. ...| research.google
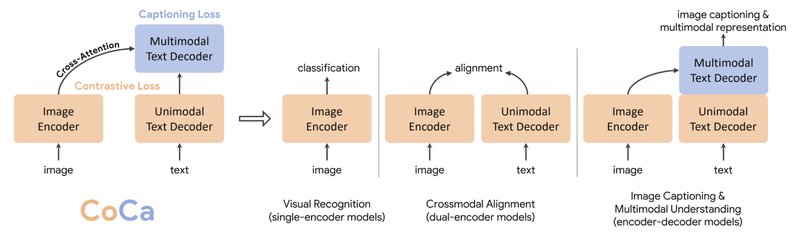
Posted by Zirui Wang and Jiahui Yu, Research Scientists, Google Research, Brain Team Oftentimes, machine learning (ML) model developers begin their...| research.google
Multimodal AI can process virtually any input, including text, images, and audio, and convert those prompts into virtually any output type.| Google Cloud
We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This ...| arXiv.org
AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principl...| arXiv.org
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact matches, we compute token similarity using contextual embeddings. We evaluate using the outputs of 363 machine translation and image captioning systems. BERTScore correlates better with human judgments and provides stronger model selection perf...| arXiv.org
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within a wide range. Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. These re...| arXiv.org
