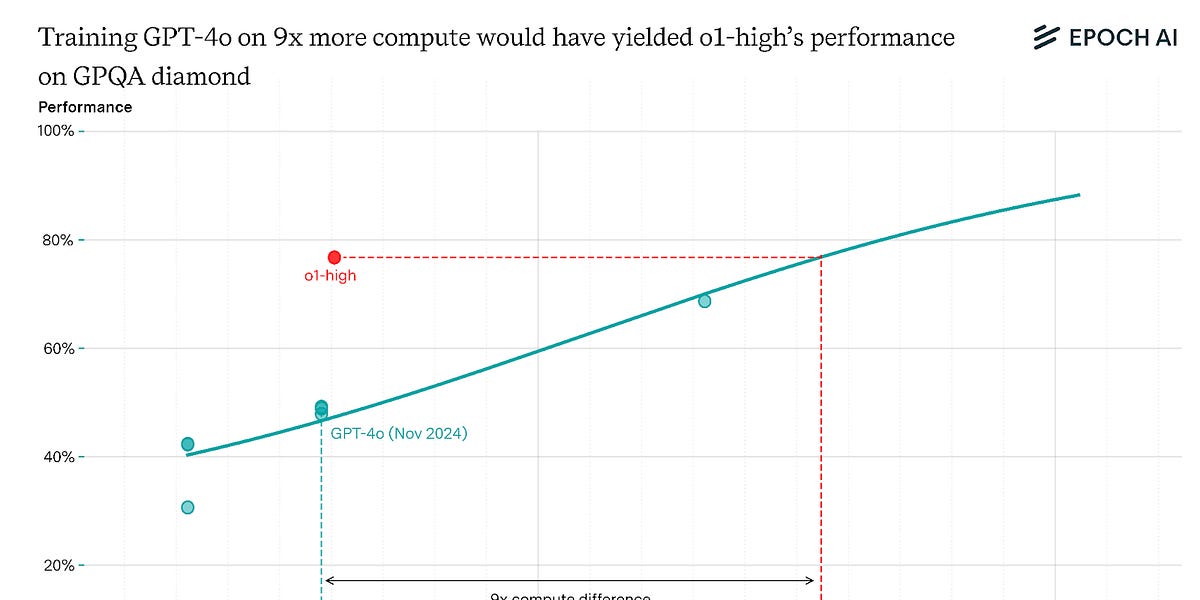
Quantifying the algorithmic improvement from reasoning models
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks| epochai.substack.com
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks| epochai.substack.com
Our database of benchmark results, featuring the performance of leading AI models on challenging tasks. It includes results from benchmarks evaluated internally by Epoch AI as well as data collected from external sources. The dashboard tracks AI progress over time, and correlates benchmark scores with key factors like compute or model accessibility.| Epoch AI

Available evidence suggests that rapid growth in reasoning training can continue for a year or so.| Epoch AI

Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.| www.anthropic.com
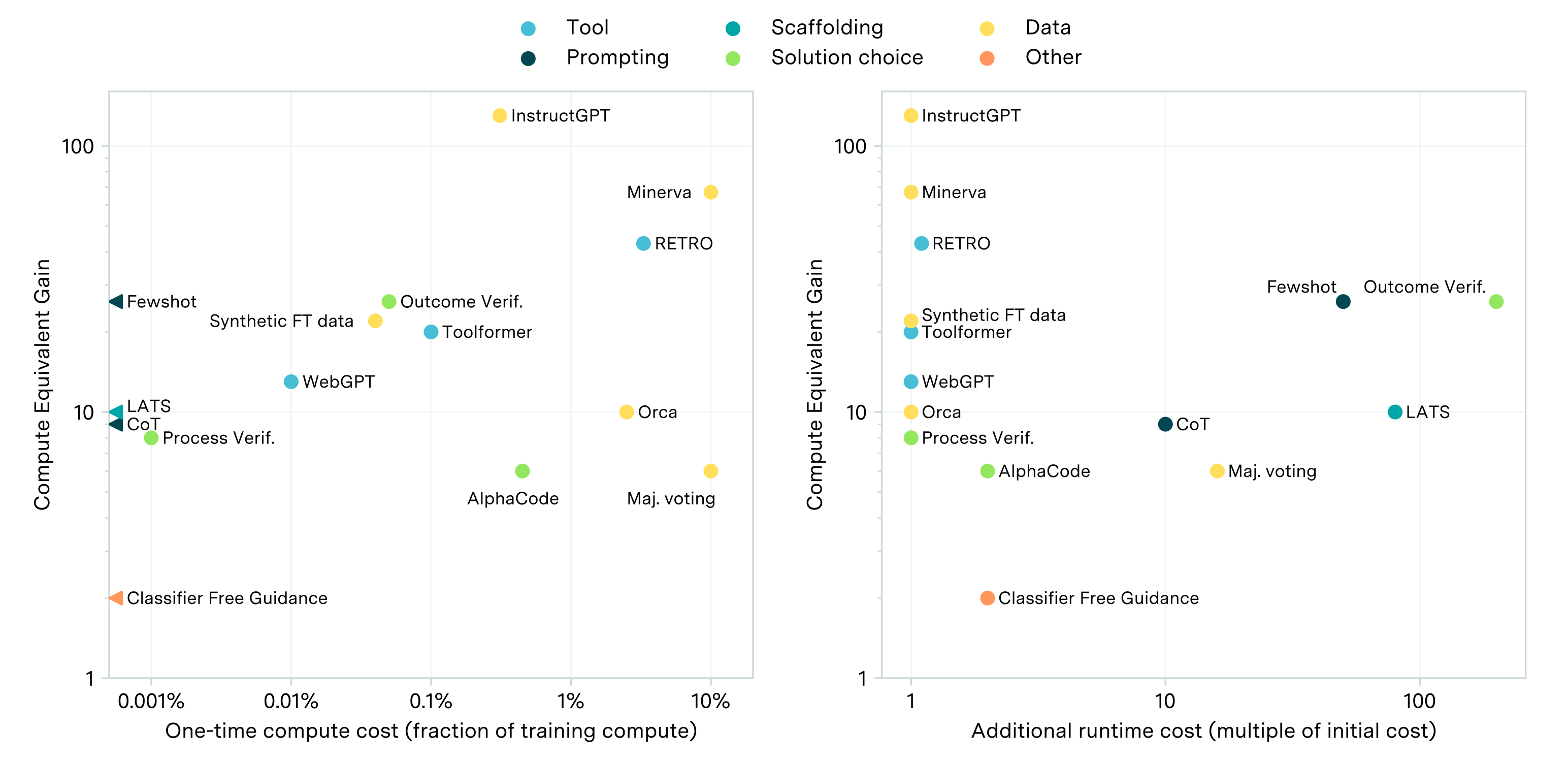
While scaling compute is key to improving LLMs, post-training enhancements can offer gains equivalent to 5-20x more compute at less than 1% of the cost.| Epoch AI
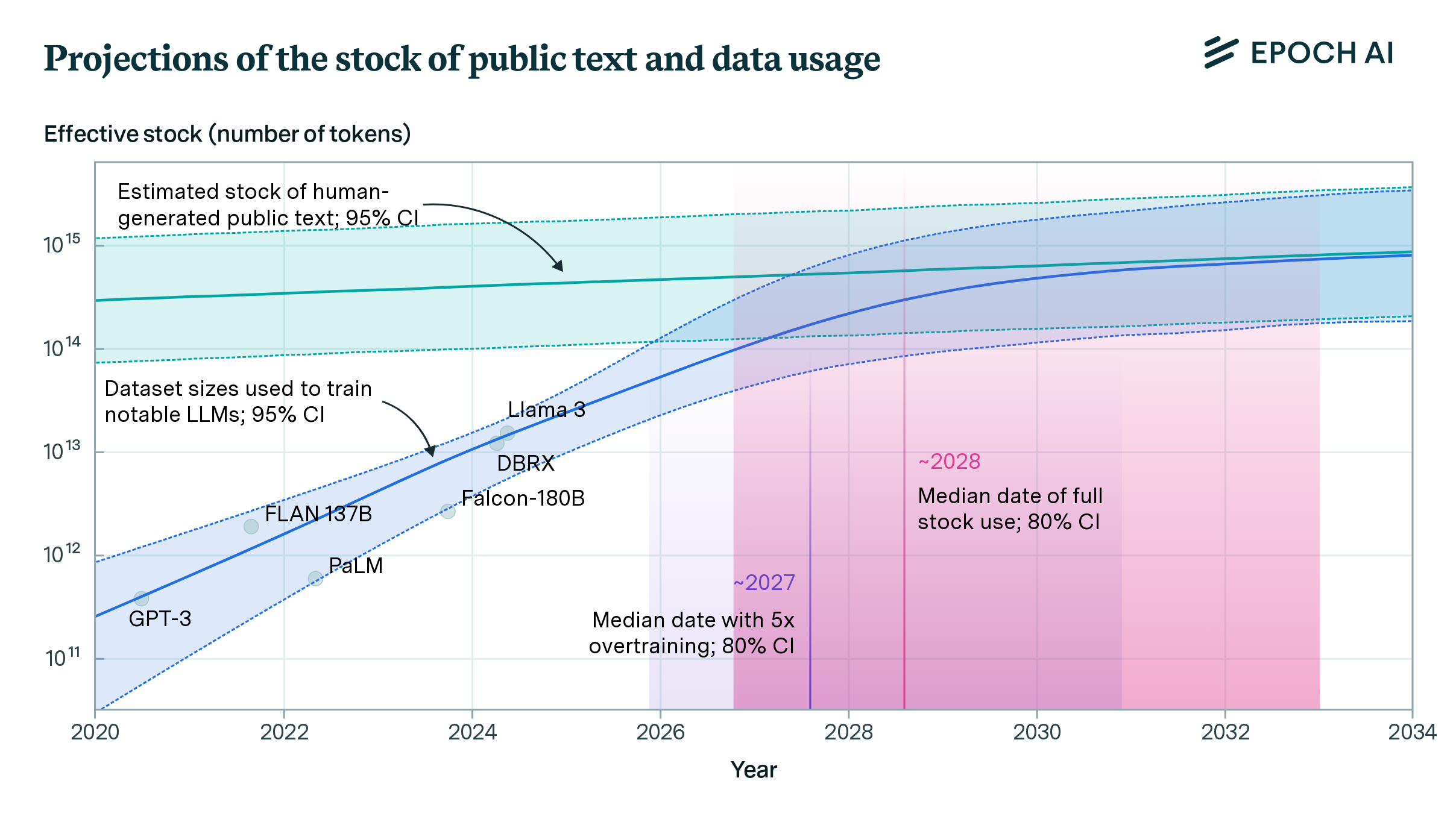
If trends continue, language models will fully utilize the stock of human-generated public text between 2026 and 2032.| Epoch AI
A refreshed, more powerful Claude 3.5 Sonnet, Claude 3.5 Haiku, and a new experimental AI capability: computer use.| www.anthropic.com

Introducing Claude 3.5 Sonnet—our most intelligent model yet. Sonnet now outperforms competitor models and Claude 3 Opus on key evaluations, at twice the speed.| www.anthropic.com
