Replication | Spanner | Google Cloud
This page describes how data is replicated in Spanner, the different| Google Cloud
This page describes how data is replicated in Spanner, the different| Google Cloud
19.4.10 Semisynchronous Replication| dev.mysql.com

TiKV, an open source distributed transactional key-value store (also a Cloud Native Computing Foundation incubating project), uses the Raft consensus algorithm to ensure strong data consistency and high availability. Raft bears many similarities to other consensus algorithms like Paxos in its ability to ensure fault-tolerance and its performance implementations, but generally easier to understand and implement. While our team has written extensively on how Raft is used in TiKV (some examples:...| tikv.org
A list of papers about distributed consensus.| Distributed Consensus Reading List
Riak was built to act as a multi-node cluster. It| docs.riak.com
High availability features¶| graphdb.ontotext.com

The specification for consensus is as follows. The first two are safety properties, the last one a liveness property. Agreement : No two n...| muratbuffalo.blogspot.com
Sometimes, reading stale data is ok — preferred, even. Let's look at "follower reads" (aka "stale reads"), a technique for getting good performance from a database accessed from multiple geographic regions.| www.cockroachlabs.com
A new open source Apache Hadoop ecosystem project, Apache Kudu completes Hadoop's storage layer to enable fast analytics on fast data| kudu.apache.org
ScyllaDB is an Apache Cassandra-compatible NoSQL data store that can handle 1 million transactions per second on a single server.| opensource.docs.scylladb.com
Introduction to the Neo4j Clustering architecture.| Neo4j Graph Data Platform

Understand how replica set elections determine the primary node in response to events like node addition, maintenance, or connectivity loss.| www.mongodb.com
SingleStore is a modern relational database for cloud and on-premises that delivers immediate insights for modern applications and analytical systems. Book a demo or trial today!| docs.singlestore.com
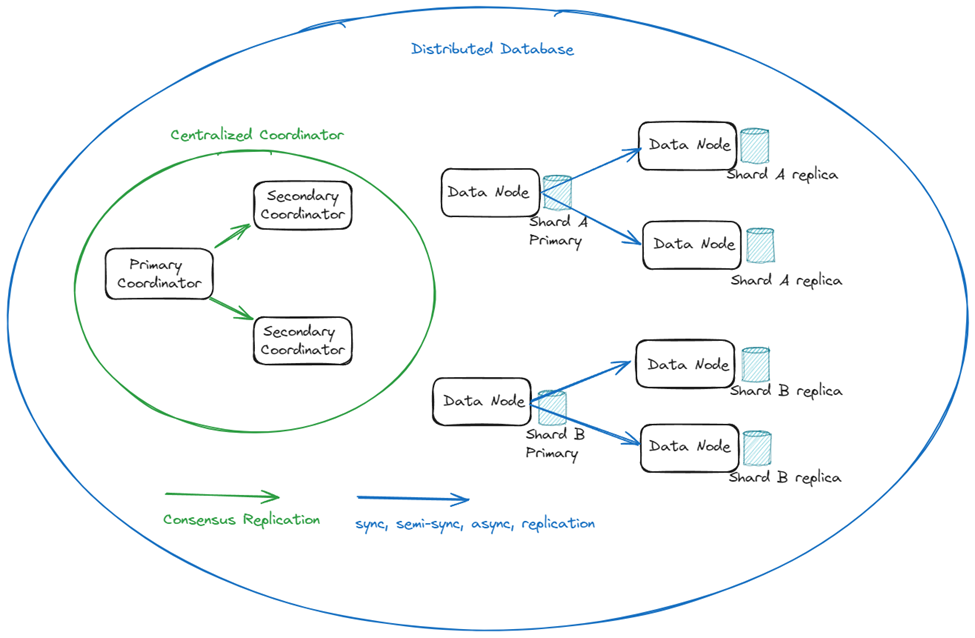
Distributed databases generally fall into two camps when it comes to architectures for maintaining high availability (HA) [1]. Both…| Medium
InfluxDB clustering is available as part of InfluxDatas commercial product offered in both managed and self-managed capacities.| InfluxData
The discussion here generally applies to any system that maintains multiple copies of| docs.hazelcast.com
Every once in awhile, you hear a story like “there was a case of a 1-Gbps NIC card on a machine that suddenly was transmitting only at 1 Kbps, which then caused a chain reaction upstream in such a way that the performance of the entire workload of a 100-node cluster was crawling at a snail's pace, effectively making the system unavailable for all practical purposes”. The stories are interesting and the postmortems are fun to read, but it's not really clear how vulnerable systems are to th...| danluu.com

How CockroachDB delivers fast, consistent reads in every region for read-mostly data. Understanding two-phase commit (2PC), uncertainty intervals, and how to deal with clock skew.| www.cockroachlabs.com
YugabyteDB replicates data using Raft consensus protocol for fault tolerance and providing consistency guarantees. The authors of Raft, Diego Ongaro and John Ousterhout, wanted to create a consensus protocol that was simpler and more understandable than the widely-used Paxos protocol. Although the authors chose the name "Raft" when thinking about logs, what can be built using them, and how to escape the island of Paxos, it is common to see Raft expanded as Replication for Availability and Fau...| YugabyteDB Docs

The replication layer of CockroachDB's architecture copies data between nodes and ensures consistency between copies.| CockroachDB Docs
Riak was built to act as a multi-node cluster. It| docs.riak.com
The Linux kernel supports high-performance zero-copy processing of streams of data by means of the splice() and sendfile() system calls, which enable the bulk movement of data as long as there is no need to inspect the content of the data as it is processed.| David Turner says…

Popularity ranking of database management systems.| DB-Engines
Detailed FoundationDB Architecture| apple.github.io
Follower Read is a highlight open-source feature that improves the throughput of the TiKV clients and reduces the load on the Raft leader. To understand how important this feature is, you’ll need a bit of background. TiKV stores data in basic units called Regions. Multiple replicas of a Region form a Raft group. When a read hotspot appears in a Region, the Region leader can become a read bottleneck for the entire system.| tikv.org
ArangoDB clusters are comprised of DB-Servers, Coordinators, and Agents, with synchronous data replication between DB-Servers and automatic failover| docs.arangodb.com
Dive into the documentation page for Memgraph and learn how to configure a cluster of Memgraph instances to achieve high availability.| Memgraph documentation
Detailed specification for Redis cluster| Docs
Jepsen analyzes the safety properties of distributed systems–most notably,| jepsen.io
