The length of time spent training notable models is growing | Epoch AI
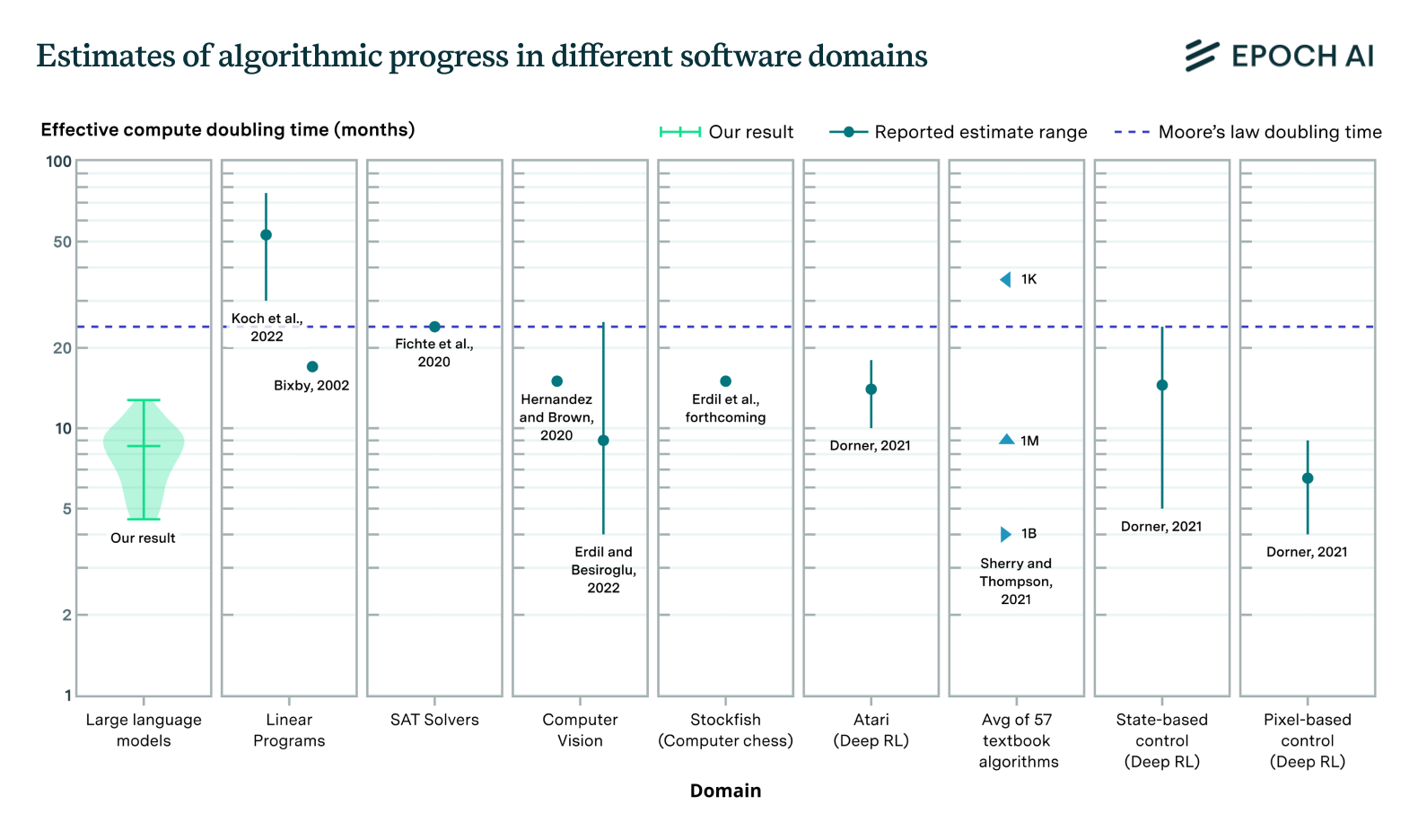
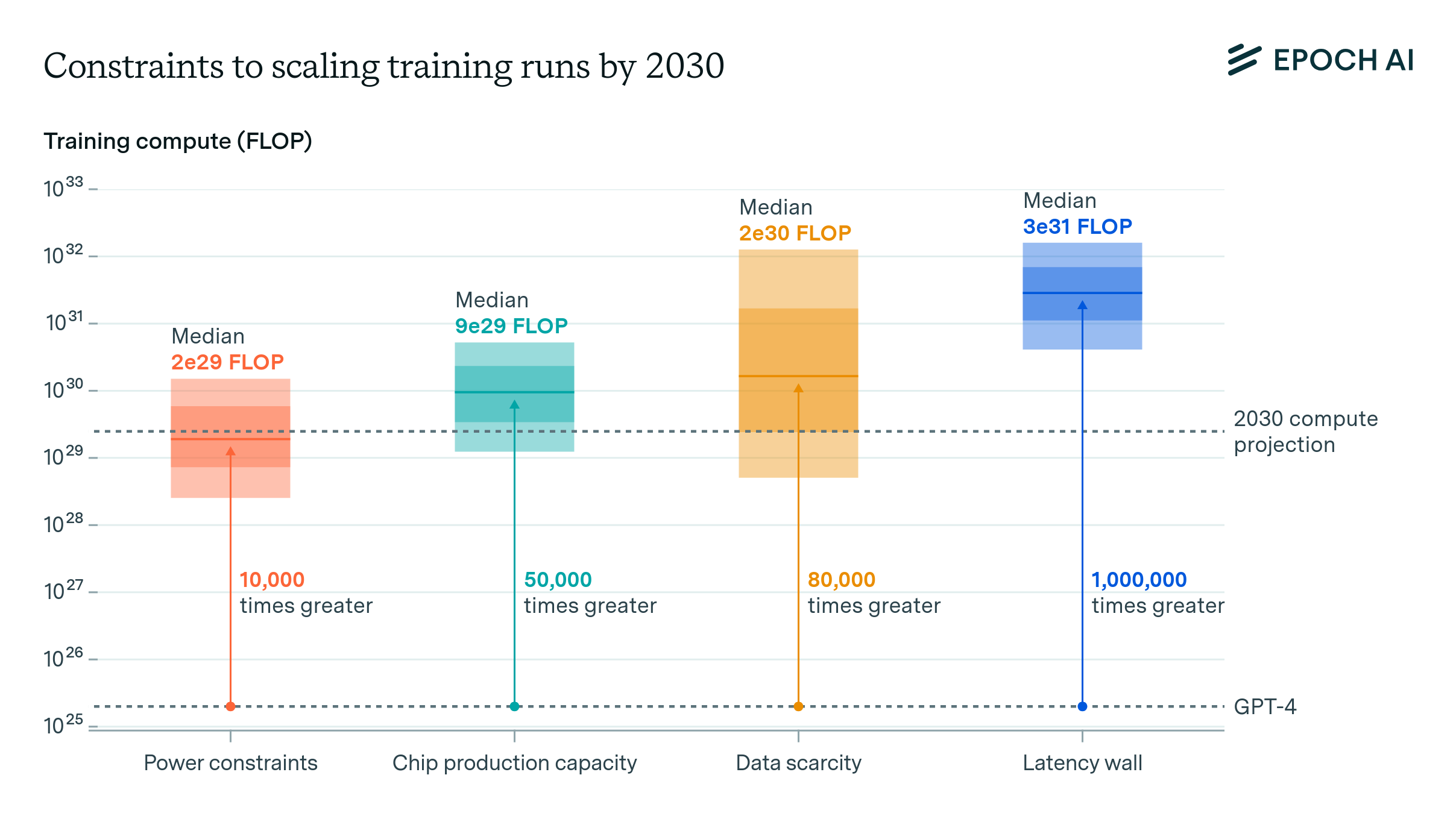
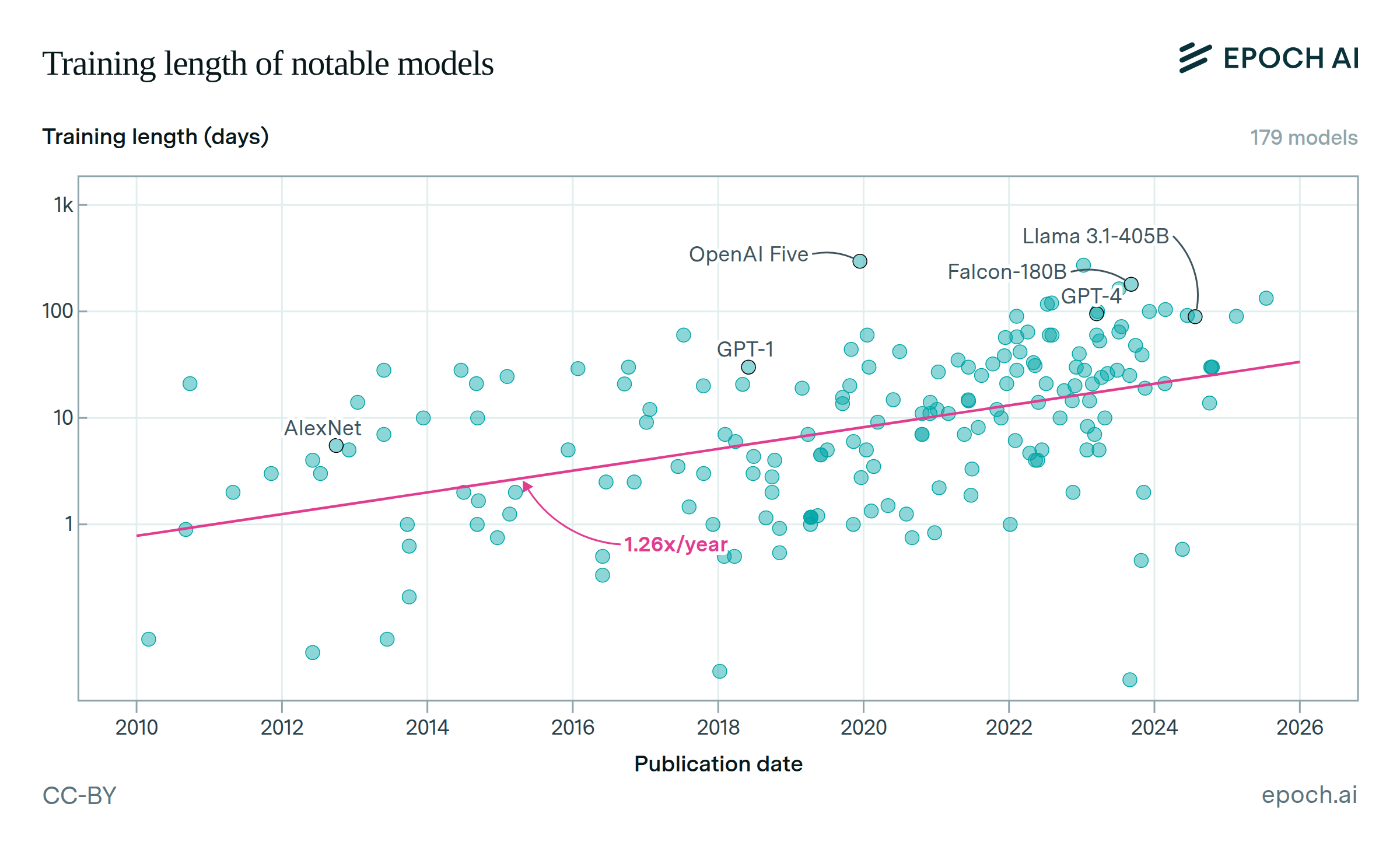
Since 2010, the length of training runs has increased by 1.2x per year among notable models, excluding those that are fine-tuned from base models. A continuation of this trend would ease hardware constraints, by increasing training compute without requiring more chips or power. However, longer training times face a tradeoff. For very long runs, waiting for future improvements to algorithms and hardware might outweigh the benefits of extended training.| Epoch AI