Attribution Patching: Activation Patching At Industrial Scale — Neel Nanda
A write-up of an incomplete project I worked on at Anthropic in early 2022, using gradient-based approximation to make activation patching far more scalable| Neel Nanda
A write-up of an incomplete project I worked on at Anthropic in early 2022, using gradient-based approximation to make activation patching far more scalable| Neel Nanda
Contributions| openaipublic.blob.core.windows.net
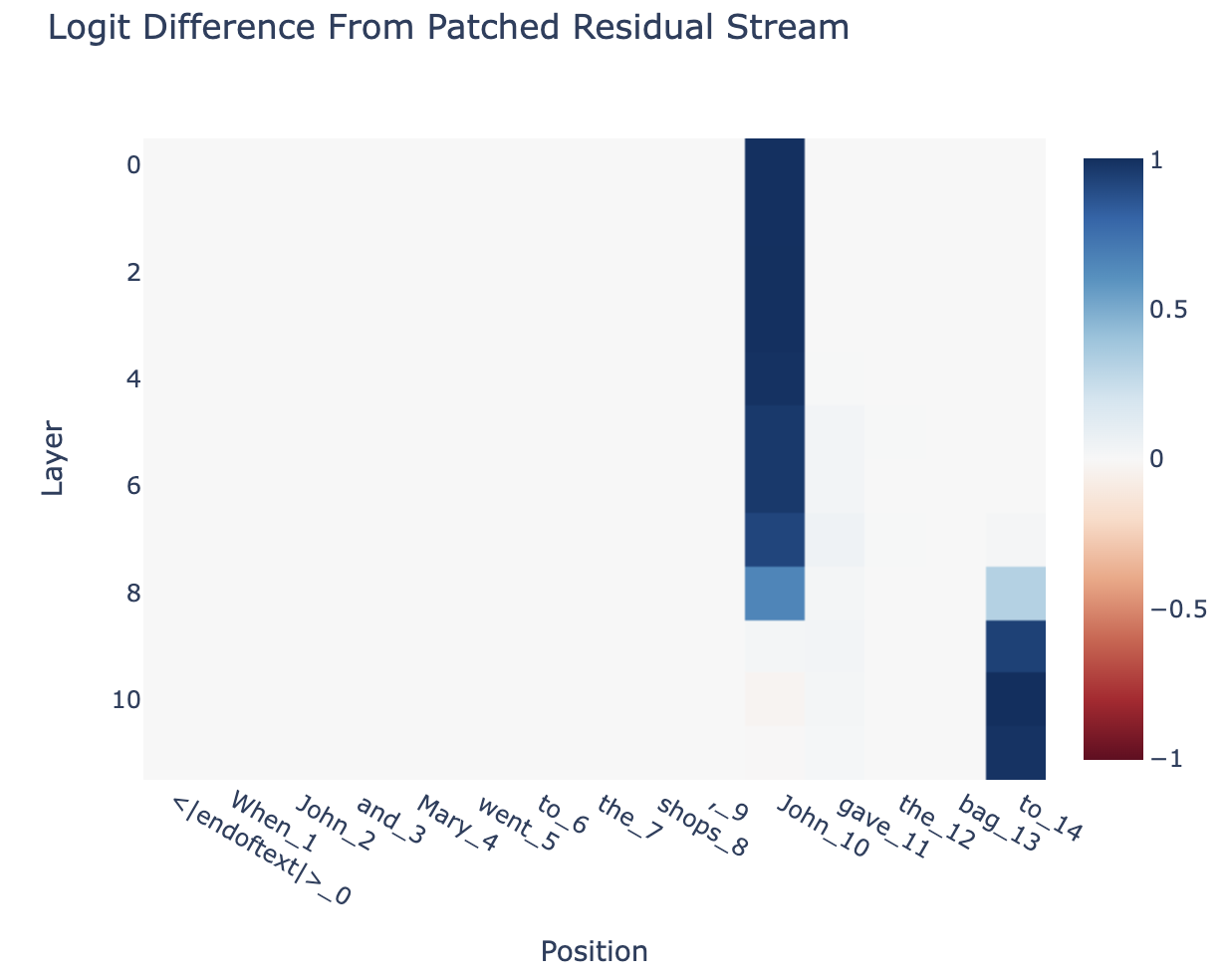
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and how they interact, we hope to be able to reason about the behavior of the entire network. The first step in that program is to identify the correct components to analyze. | transformer-circuits.pub
Mechanistic interpretability seeks to reverse engineer neural networks, similar to how one might reverse engineer a compiled binary computer program. After all, neural network parameters are in some sense a binary computer program which runs on one of the exotic virtual machines we call a neural network architecture.| transformer-circuits.pub
