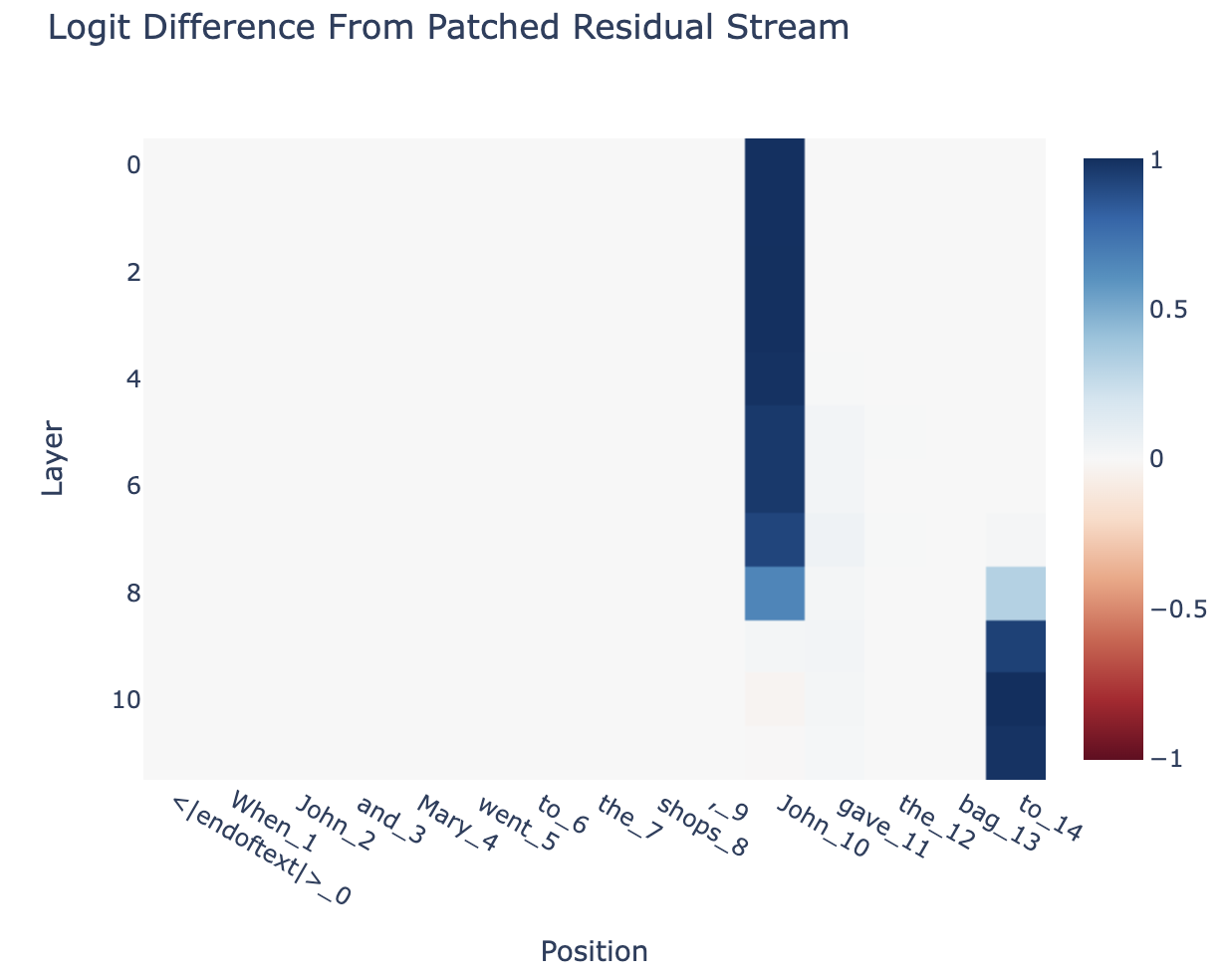
Attribution Patching: Activation Patching At Industrial Scale — Neel Nanda
A write-up of an incomplete project I worked on at Anthropic in early 2022, using gradient-based approximation to make activation patching far more scalable| Neel Nanda
A write-up of an incomplete project I worked on at Anthropic in early 2022, using gradient-based approximation to make activation patching far more scalable| Neel Nanda
Appearance | dynalist.io
This post relates an observation I've made in my work with GPT-2, which I have not seen made elsewhere. …| www.lesswrong.com

A mystery Large Language Models (LLM) are on fire, capturing public attention by their ability to provide seemingly impressive completions to user prompts (NYT coverage). They are a delicate combination of a radically simplistic algorithm with massive amounts of data and computing power. They are trained by playing a guess-the-next-word| The Gradient
