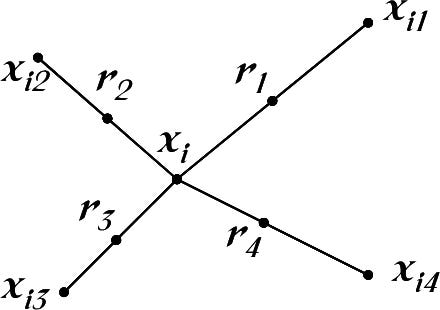
Balanced samples are good, balancing samples is bad
We should lower our expectations from balancing. Sampling might not improve class separation, and even if it does, it will typically come at a cost to calibration and log loss.| simplicityissota.substack.com
