Are you part of an under-resourced team where adding time-saving dbt (data build tool) features take a back seat to delivering new datasets? Do you want to incorporate time (& money) saving dbt processes but need more time? While focussing on delivery may help in the short term, the delivery speed will suffer without proper workflow! A good workflow will save time, prevent bad data, and ensure high development speed! Imagine the time (& mental pressure) savings if you didn't have to validate ...| www.startdataengineering.com
Introduction Poetry is a tool for dependency management and packaging in Python. It allows you to declare the libraries your project depends on and it will manage (install/update) them for you. Poetry offers a lockfile to ensure repeatable installs, and can build your project for distribution. System requirements Poetry requires Python 3.9+. It is multi-platform and the goal is to make it work equally well on Linux, macOS and Windows.| python-poetry.org
Efficient Data Processing in SQLA guide to understanding the core concepts of distributed data storage & processing, analytical functions, and query optimizations in your data warehouse.You want to be able to write efficient data processing pipelines in SQL, but you don't know where to start!There are too many topics to learn to get proficient at efficient data processing in SQL, like optimizing queries, partitioning, parallelism, data modeling, best practices, etc. It is overwhelming to have...| Gumroad
This post goes over what the ETL and ELT data pipeline paradigms are. It tries to address the inconsistency in naming conventions and how to understand what they really mean. Finally ends with a comparison of the 2 paradigms and how to use these concepts to build efficient and scalable data pipelines.| www.startdataengineering.com
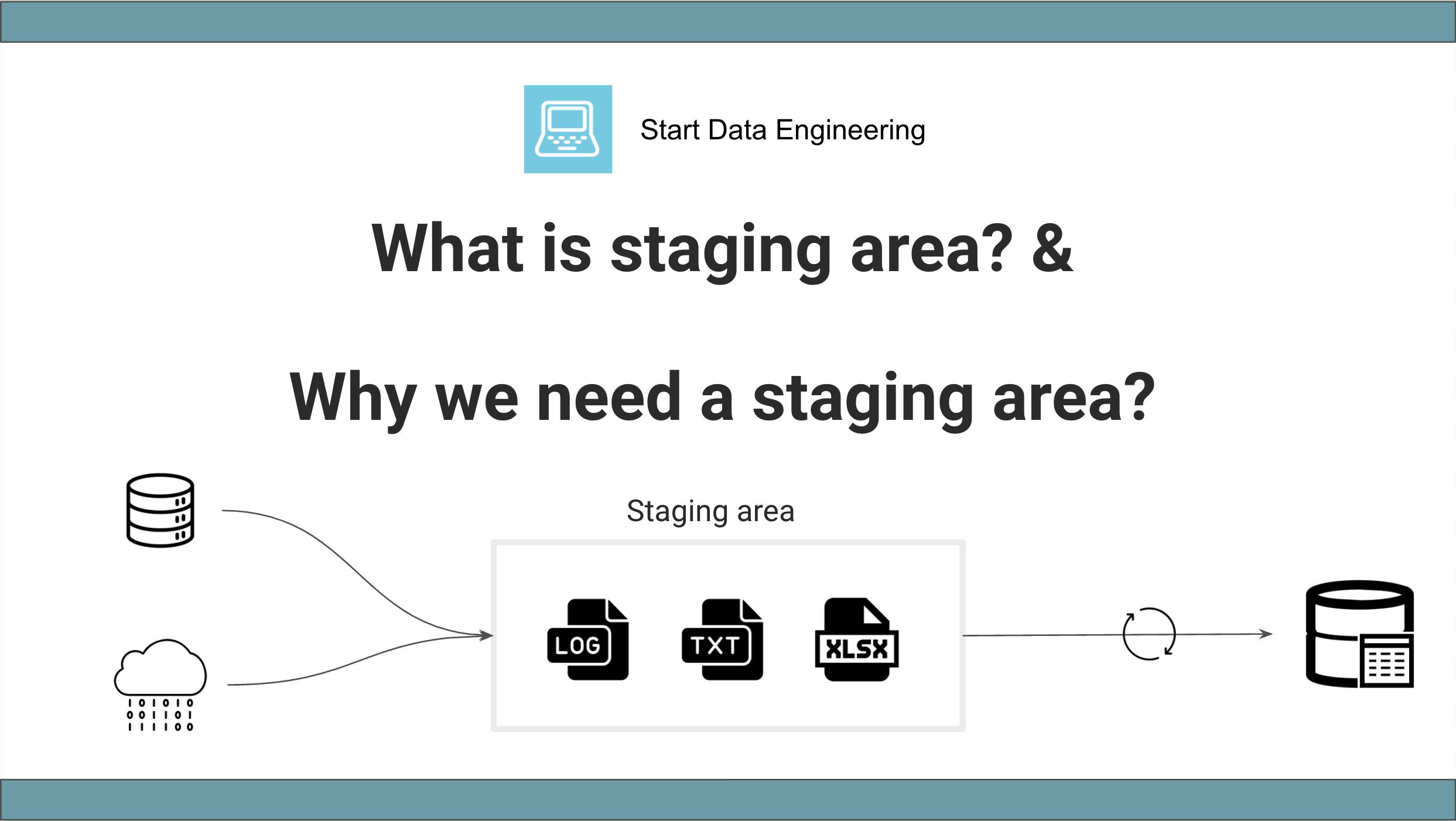
Wondering what is staging and why you need one for your data pipelines? Then this post is for you. In this post, we will go over what exactly a staging area is and why it is crucial for data pipelines.| www.startdataengineering.com
Setting up an ELT data-ops workflow with multiple environments for developers is often extremely time consuming. What if there was a way to speed up this process, so that you could concentrate on modeling your data and delivering value to your end users? The good news is that there is a way. You can leverage dbt cloud to setup an ELT data-ops workflow in a very short time. In this post, we cover how to setup a data-ops workflow for an ELT system. We will go over how to setup dbt, snowflake, C...| www.startdataengineering.com
Wondering how to store a dimension table's history over time and how to join these historical dimension tables with fact tables for analytical querying ? Then this post is for you. In this post, we will go over a popular dimension modeling technique called SCD2, which preserves historical changes. We will also see how to join a fact table with an SCD2 table to get accurate point in time information.| www.startdataengineering.com
With the advent of powerful data warehouses like snowflake, bigquery, redshift spectrum, etc that allow separation of storage and execution, it has become very economical to store data in the data warehouse and then transform them as required. This post goes over how to design such a ELT system using stitch and DBT. The main objective is to keep the code complexity and server management low, while automating as much as possible| www.startdataengineering.com
In this article we aim to go over the reasoning behind why someone might want to use dbt. If you are interested in learning dbt checkout this article . Some common questions from Data Engineers about dbt are it is not very clear to me why would I use dbt instead of running SQL queries on Airflow| www.startdataengineering.com
Using dbt you can test the output of your sql transformations. If you have wondered how to "unit test" your sql transformations in dbt, then this post is for you. In this post, we go over how to write unit tests for your sql transformations with mock inputs/outputs and test them locally. This helps keep the development cycle shorter and enables you to follow a TDD approach for your sql based data pipelines.| www.startdataengineering.com