This post goes over what the ETL and ELT data pipeline paradigms are. It tries to address the inconsistency in naming conventions and how to understand what they really mean. Finally ends with a comparison of the 2 paradigms and how to use these concepts to build efficient and scalable data pipelines.| www.startdataengineering.com
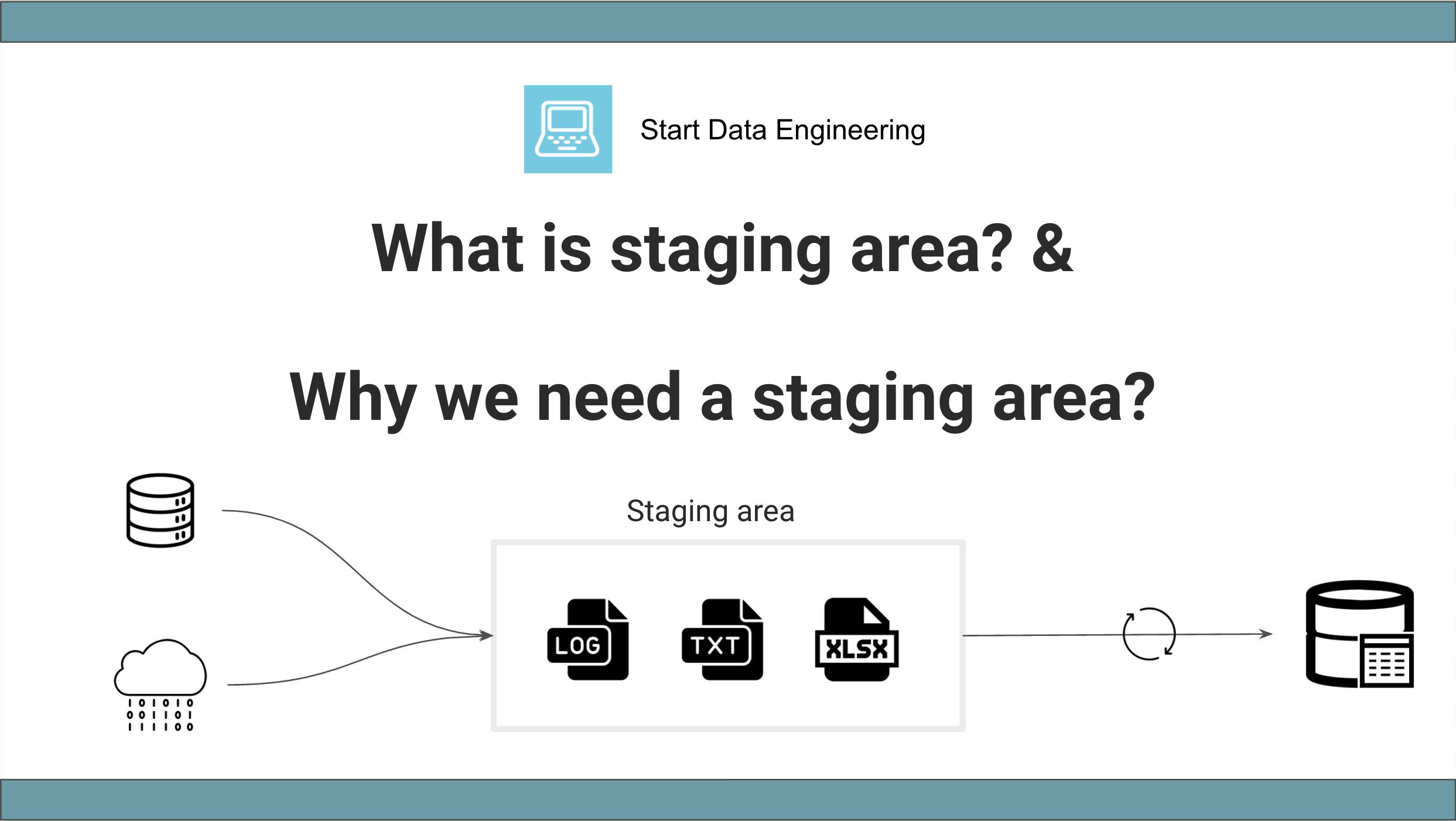
Wondering what is staging and why you need one for your data pipelines? Then this post is for you. In this post, we will go over what exactly a staging area is and why it is crucial for data pipelines.| www.startdataengineering.com
Working with a dataset that is too large to fit in memory? Then this post is for you. In this post, we will write memory efficient data pipelines using python generators. We also cover the common generator patterns you will need for your data pipelines.| www.startdataengineering.com
Wondering how to execute a spark job on an AWS EMR cluster, based on a file upload event on S3? Then this post if for you. In this post we go over how to trigger spark jobs on an AWS EMR cluster, using AWS Lambda. The lambda function will execute in response to an S3 upload event. We will go over this event driven pattern with code snippets and set up a fully functioning pipeline.| www.startdataengineering.com
Unable to find practical examples of idempotent data pipelines? Then, this post is for you. In this post, we go over a technique that you can use to make your data pipelines professional and data reprocessing a breeze.| www.startdataengineering.com