
Canonical URLs: A Beginner‘s Guide to Canonical Tags
A canonical URL is the version of a webpage that search engines treat as “main“ when there are duplicates.| Semrush Blog
A canonical URL is the version of a webpage that search engines treat as “main“ when there are duplicates.| Semrush Blog

Crawlability refers to a search engine‘s ability to access web content and index it for ranking in search results.| Semrush Blog

An XML sitemap is a file that tells search engines which URLs it should store to serve in search results.| Semrush Blog

Learn top internal linking strategies and get a free template to optimize your site‘s SEO and user experience.| Semrush Blog
Must-have premium plugins| WordPress.com

Website architecture refers to the structure of websites. Learn best practices for organizing your site for SEO.| Semrush Blog

Keyword cannibalization is an SEO issue that occurs when multiple pages on a site serve the same purpose.| Semrush Blog

Backlinks are links that one site gets from another. They can drive traffic and benefit the linked site‘s SEO.| Semrush Blog

Track daily Google rankings for mobile and desktop. Analyze SERP features (Featured snippet, local map pack, AMP etc). Create beautiful PDF reports.| Semrush
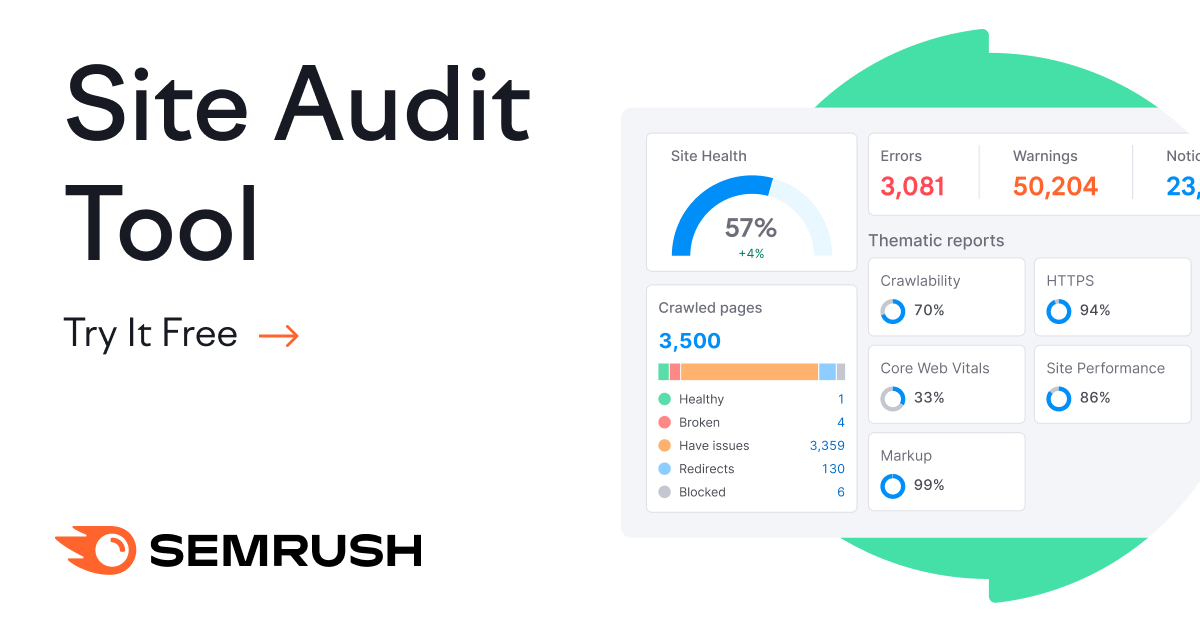
Free tool to run a website audit, check for SEO issues, and apply fixes that grow traffic and visibility.| Semrush

A URL slug is the last part of a URL that identifies a particular page on your website.| Semrush Blog

Google PageRank measures a webpage’s importance based on the quality and quantity of links pointing to it.| Semrush Blog
The Hypertext Transfer Protocol (HTTP) is a stateless \%application- level protocol for distributed, collaborative, hypertext information systems. This document defines the semantics of HTTP/1.1 messages, as expressed by request methods, request header fields, response status codes, and response header fields, along with the payload of messages (metadata and body content) and mechanisms for content negotiation.| IETF Datatracker
