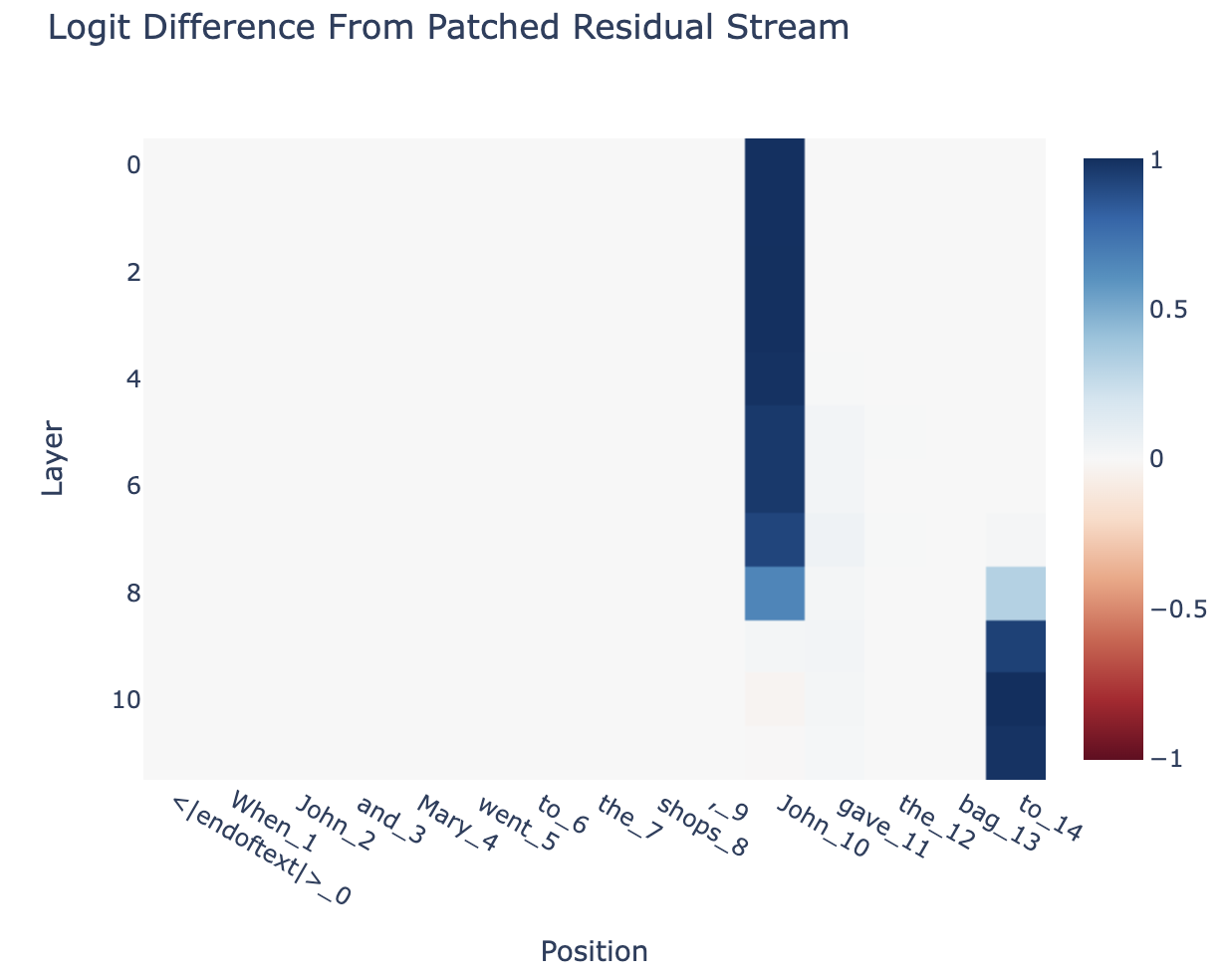
New paper walkthrough: Interpretability in the Wild: A Circuit for Indirect Object Identification In GPT-2 Small is a really exciting new mechanistic interpretability paper from Redwood Research. They reverse engineer a 26(!) head circuit in GPT-2 Small, used to solve Indirect Object Identification: the task of understanding that the sentence "After John and Mary went to the shops, John gave a bottle of milk to" should end in Mary, not John.| Neel Nanda
These are notes taken during a call with Itay Yona , an expert in software/hardware reverse engineering (SRE). Itay gave me an excellent distillation of key ideas and mindsets in the field, and we discussed analogies/disanalogies to mechanistic interpretability of neural networks. I’m ge| Neel Nanda
Co-authored by Neel Nanda and Jess Smith Check out Concrete Steps for Getting Started in Mechanistic Interpretability for a better starting point Why does this exist? People often get intimidated when trying to get into AI or AI Alignment research. People often think that the gulf betwee| Neel Nanda
Deprecated, see a much more up-to-date post here Disclaimer : This post mostly links to resources I've made. I feel somewhat bad about this, sorry! Transformer MI is a pretty young and small field and there just aren't many people making educational resources tailored to it. So| Neel Nanda
A rough post exploring the emergent positional embedding hypothesis - rather than representing "this is the token in position 5" models may represent eg "this token is the second name in the sentence"| Neel Nanda
A write-up of an incomplete project I worked on at Anthropic in early 2022, using gradient-based approximation to make activation patching far more scalable| Neel Nanda