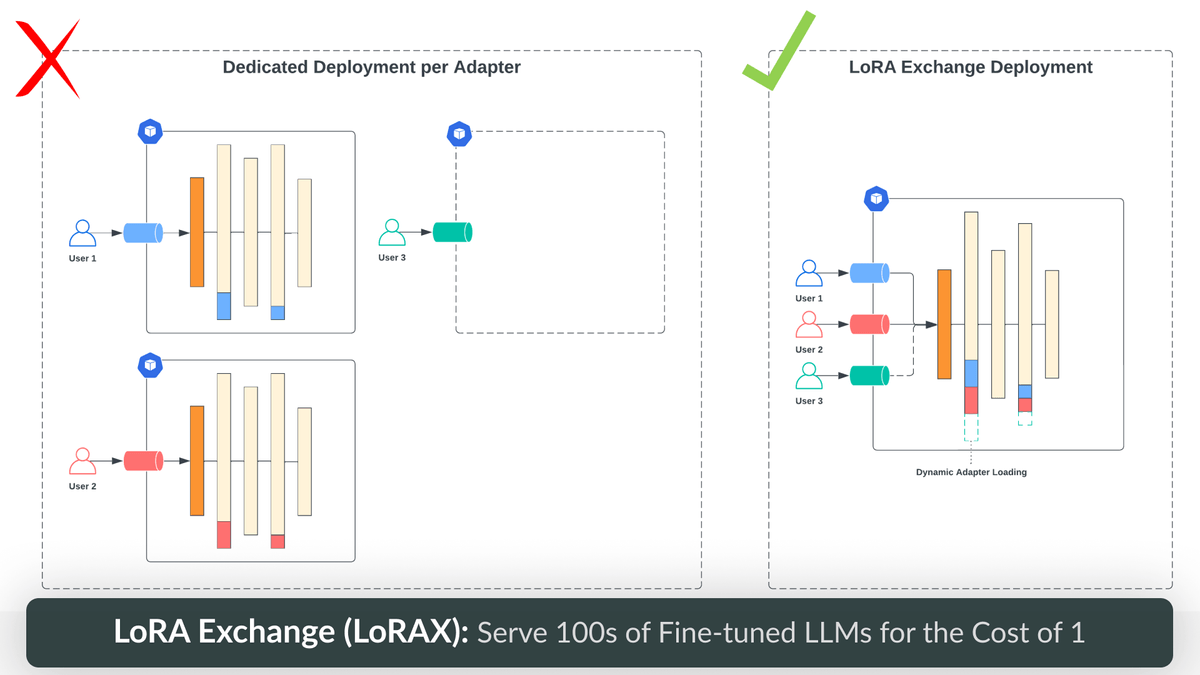
LoRA Exchange (LoRAX): Serve 100s of Fine-Tuned LLMs for the Cost of 1 - Predibase - Predibase
We’ve build a new type of LLM serving infrastructure optimized for productionizing many fine-tuned models together with a shared set of GPU resources, allowing teams to recognize 100x cost savings on model serving.| predibase.com
