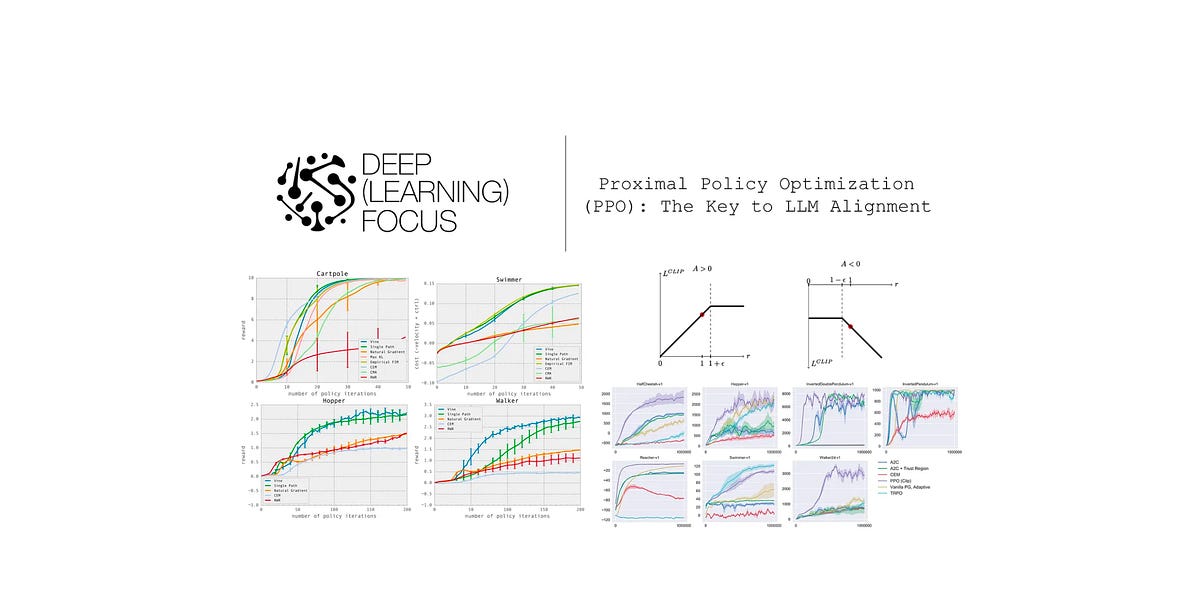
Proximal Policy Optimization (PPO): The Key to LLM Alignment
Modern policy gradient algorithms and their application to language models...| cameronrwolfe.substack.com
Modern policy gradient algorithms and their application to language models...| cameronrwolfe.substack.com
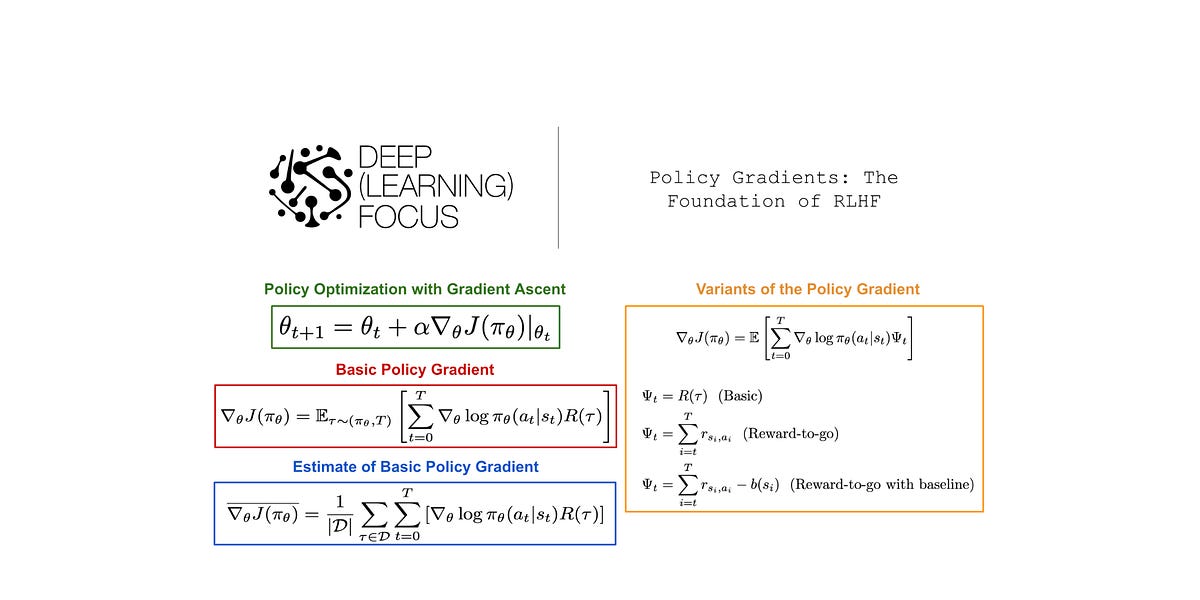
Understanding policy optimization and how it is used in reinforcement learning...| cameronrwolfe.substack.com
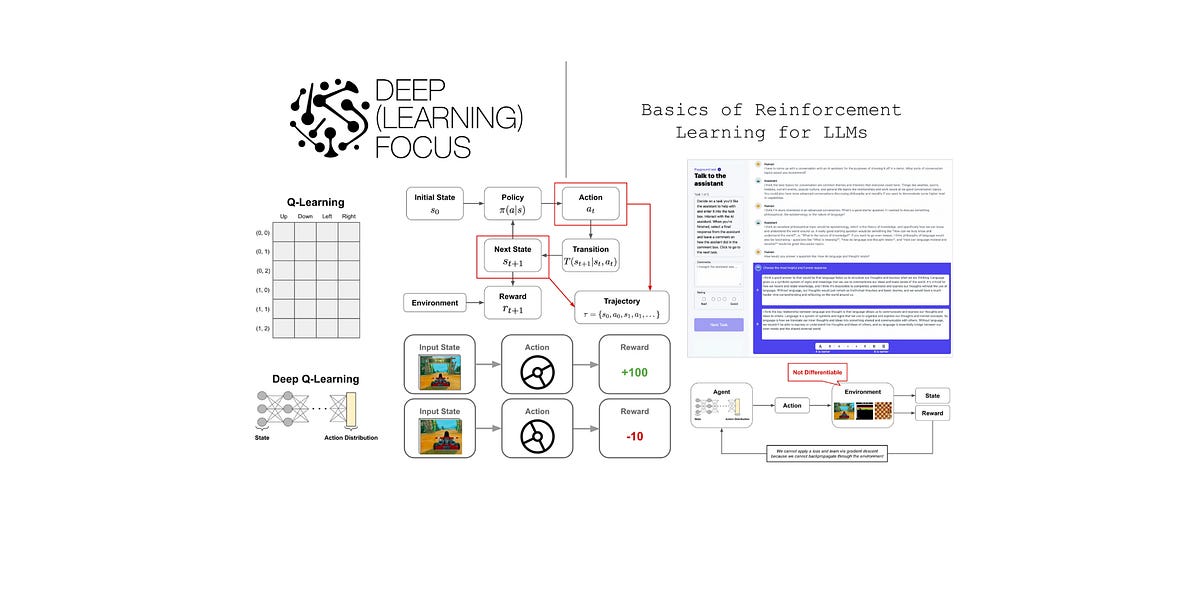
Understanding the problem formulation and basic algorithms for RL..| cameronrwolfe.substack.com

Understanding how SFT works from the idea to a working implementation...| cameronrwolfe.substack.com
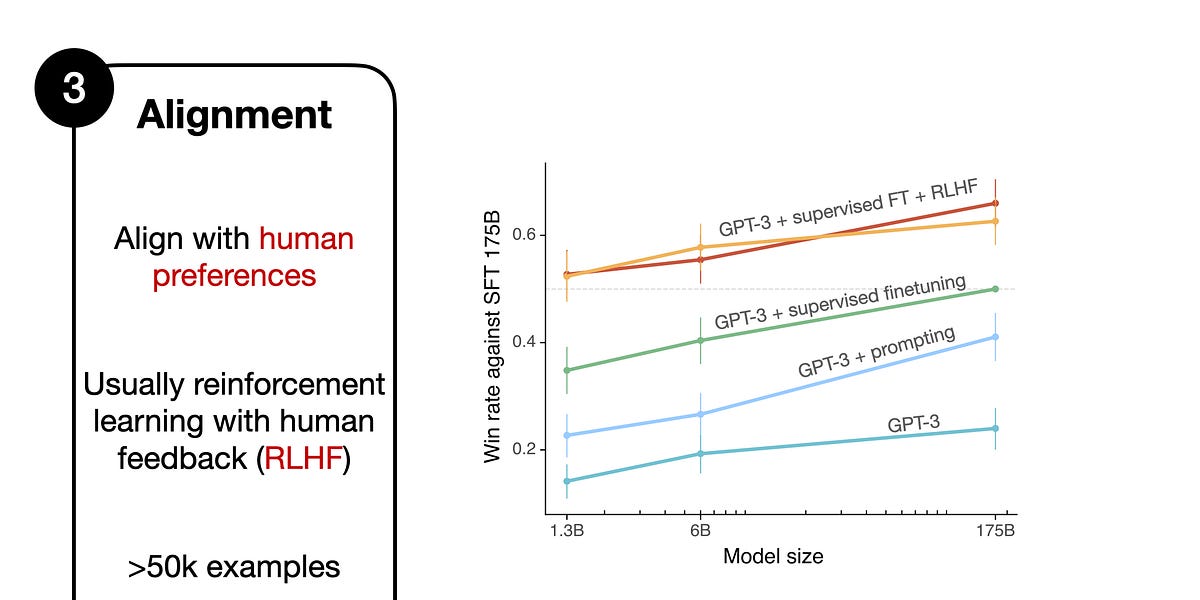
I frequently reference a process called Reinforcement Learning with Human Feedback (RLHF) when discussing LLMs, whether in the research news or tutorials.| magazine.sebastianraschka.com

We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
