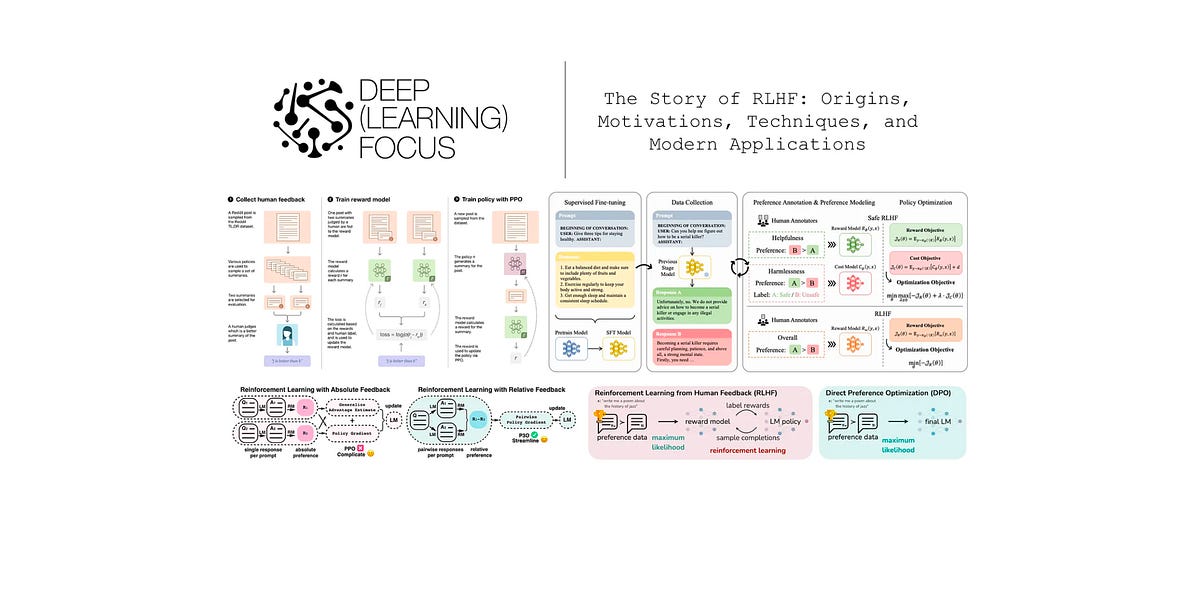
The Story of RLHF: Origins, Motivations, Techniques, and Modern Applications
How learning from human feedback revolutionized generative language models...| cameronrwolfe.substack.com
How learning from human feedback revolutionized generative language models...| cameronrwolfe.substack.com
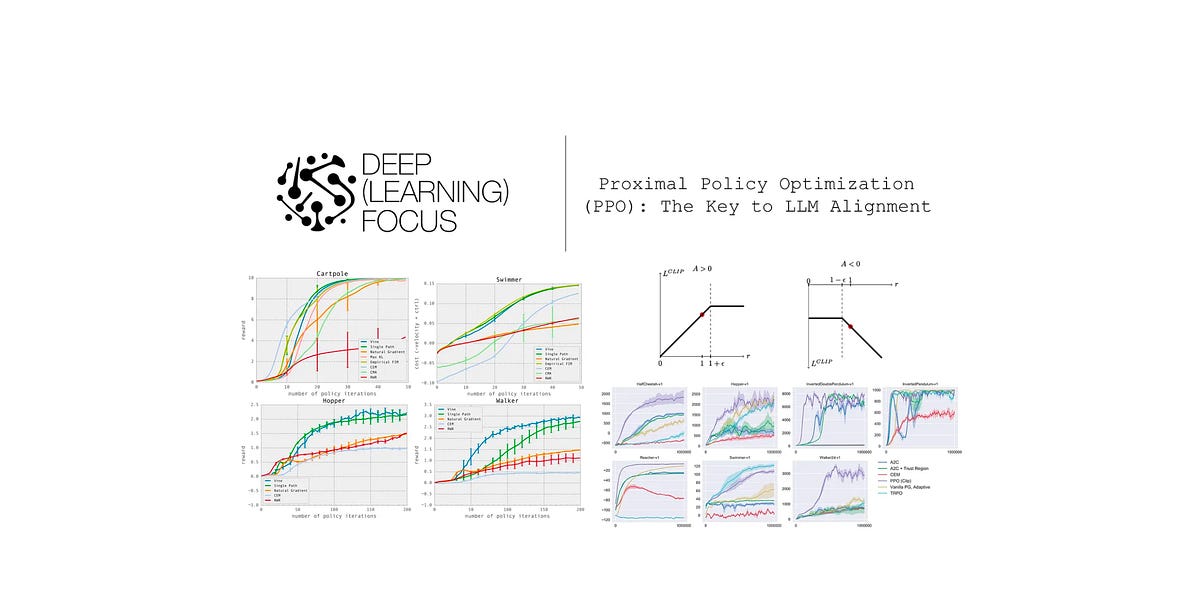
Modern policy gradient algorithms and their application to language models...| cameronrwolfe.substack.com
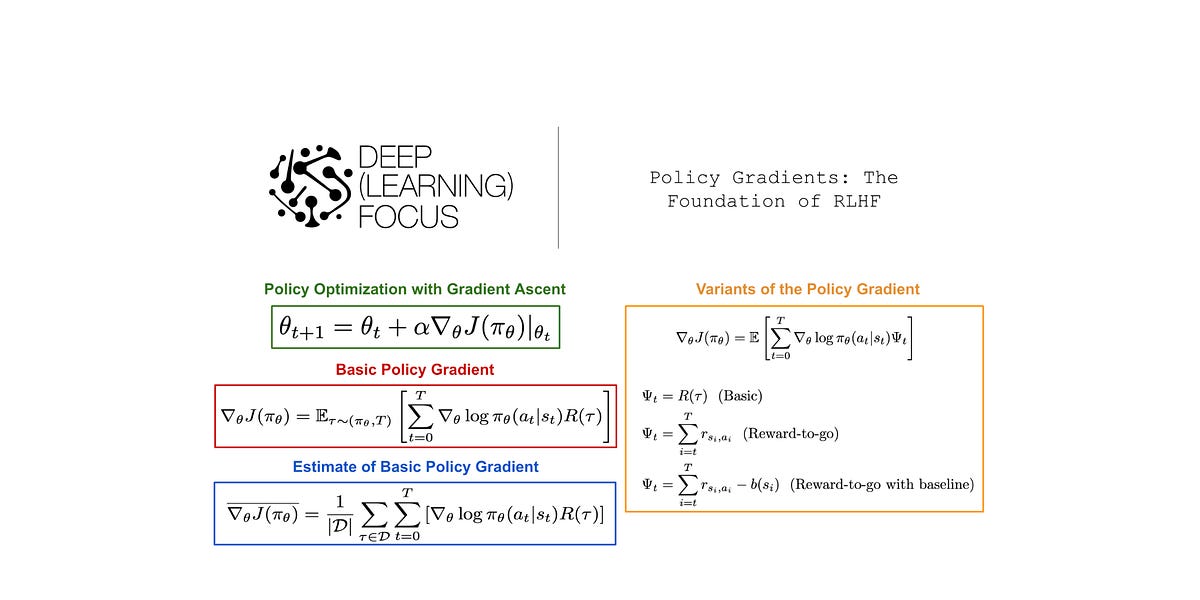
Understanding policy optimization and how it is used in reinforcement learning...| cameronrwolfe.substack.com
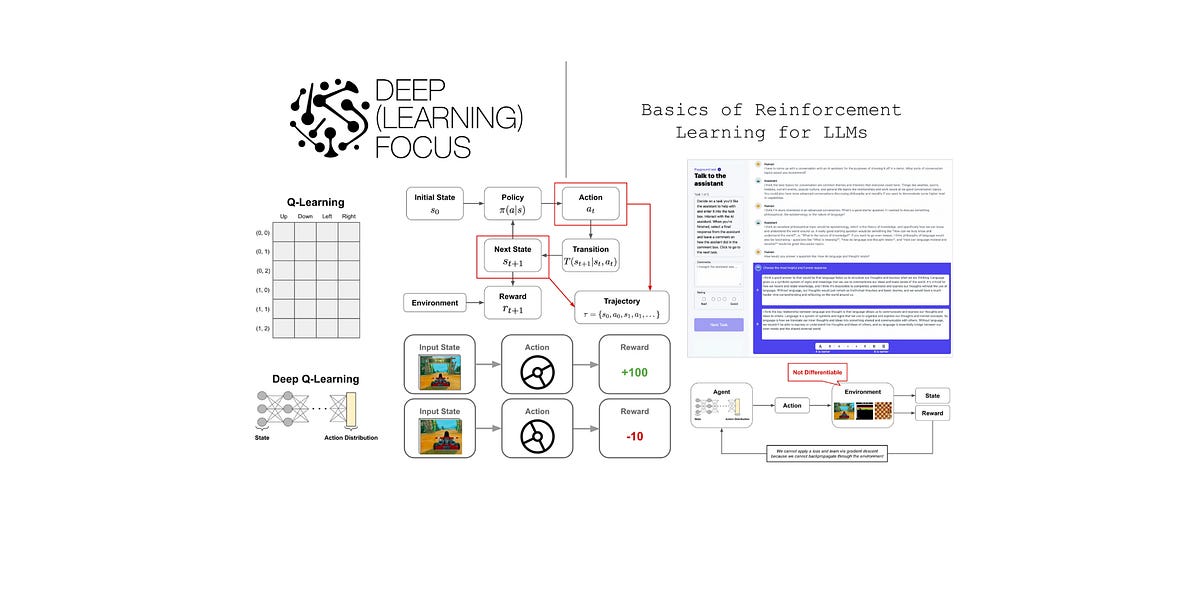
Understanding the problem formulation and basic algorithms for RL..| cameronrwolfe.substack.com
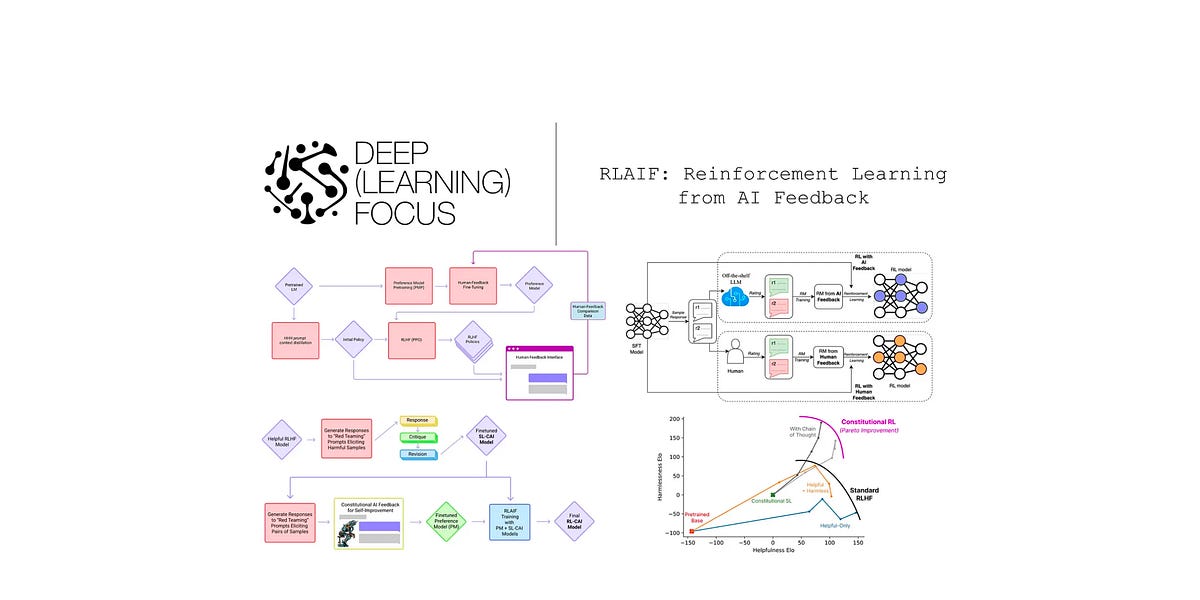
Making alignment via RLHF more scalable by automating human feedback...| cameronrwolfe.substack.com

Understanding how SFT works from the idea to a working implementation...| cameronrwolfe.substack.com
Understanding LSTM Networks| colah.github.io
