
Introducing: Undivided Attention - VAST Data
VAST introduces new Undivided Attention acceleration tools to reduce the complexity of deploying shared AI inference services at scale.| VAST Data
VAST introduces new Undivided Attention acceleration tools to reduce the complexity of deploying shared AI inference services at scale.| VAST Data

A Tale of Two Softwares: In a world where AI is revolutionizing the way we interact with technology, a new type of software emerges: AI Software (AISW). But with great power comes great responsibil…| SIGPLAN Blog
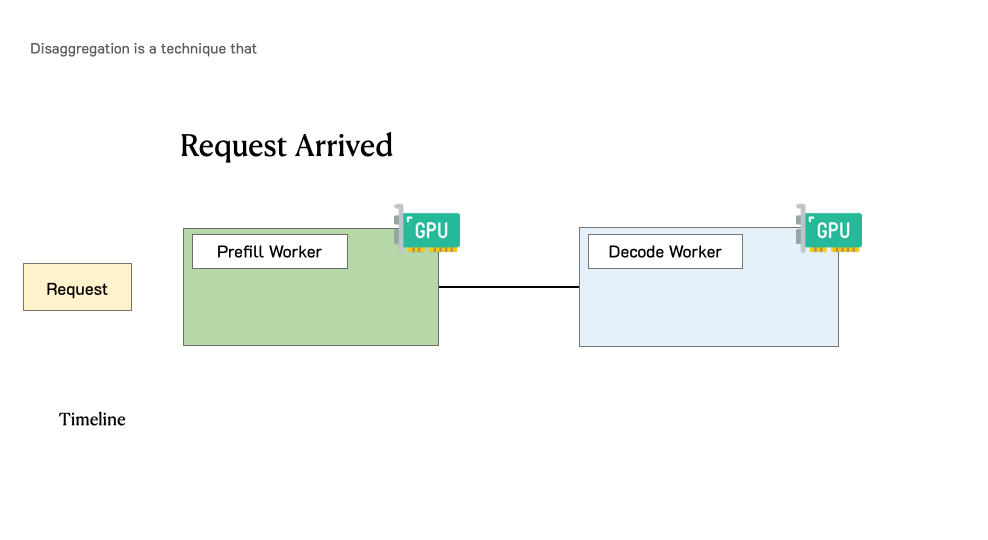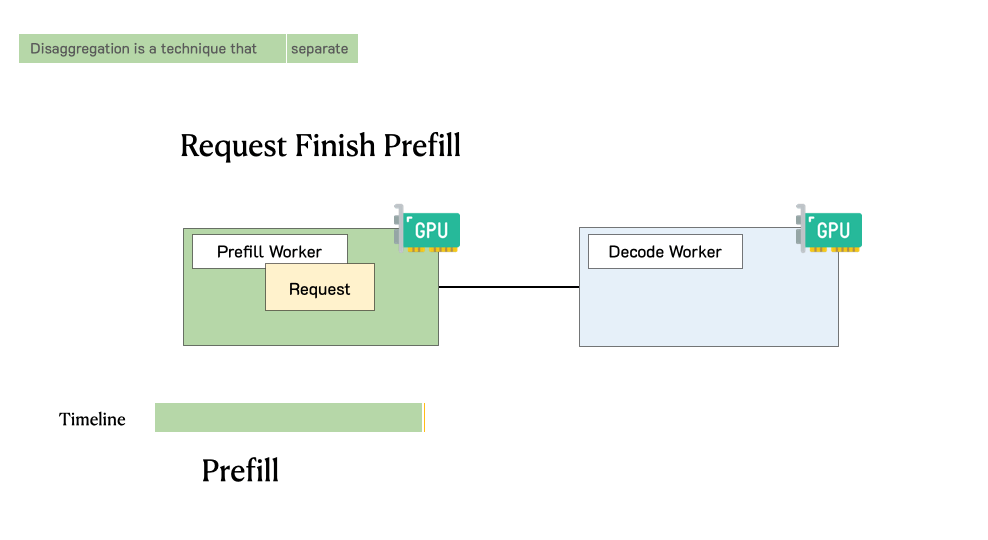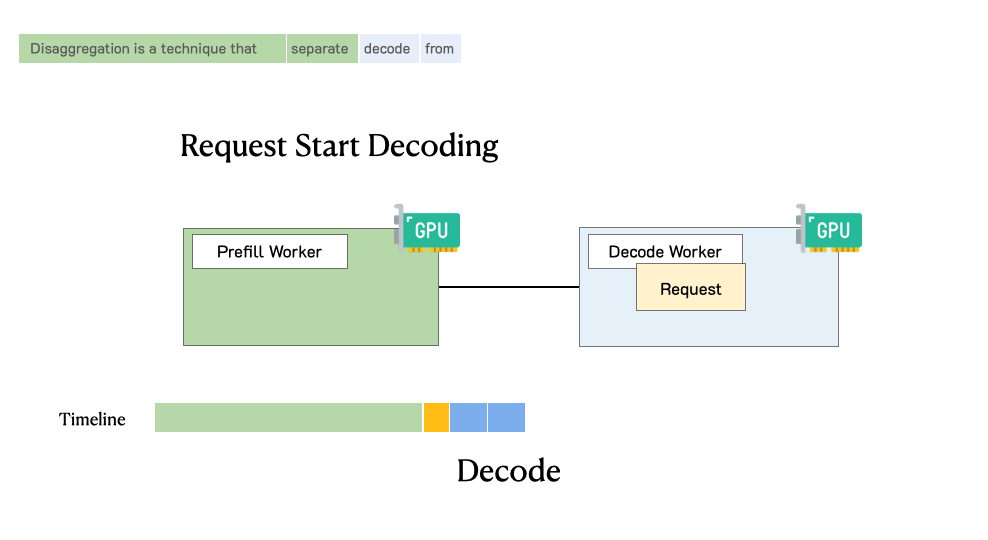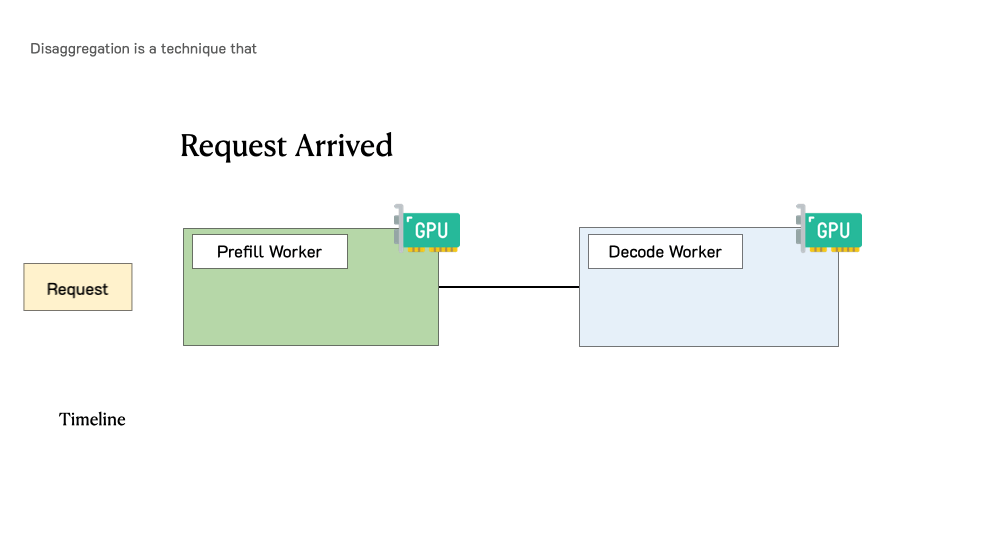
TL;DR: LLM apps today have diverse latency requirements. For example, a chatbot may require a fast initial response (e.g., under 0.2 seconds) but moderate speed in decoding which only needs to match human reading speed, whereas code completion requires a fast end-to-end generation time for real-time code suggestions. In this blog post, we show existing serving systems that optimize throughput are not optimal under latency criteria. We advocate using goodput, the number of completed requests p...| hao-ai-lab.github.io

In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.| Anyscale
