A small number of samples can poison LLMs of any size \ Anthropic
Anthropic research on data-poisoning attacks in large language models| www.anthropic.com
Anthropic research on data-poisoning attacks in large language models| www.anthropic.com

Highlights the desire to replace tokenization with a general method that better leverages compute and data. We'll see tokenization's fragility and review the Byte Latent Transformer arch.| ⛰️ lucalp
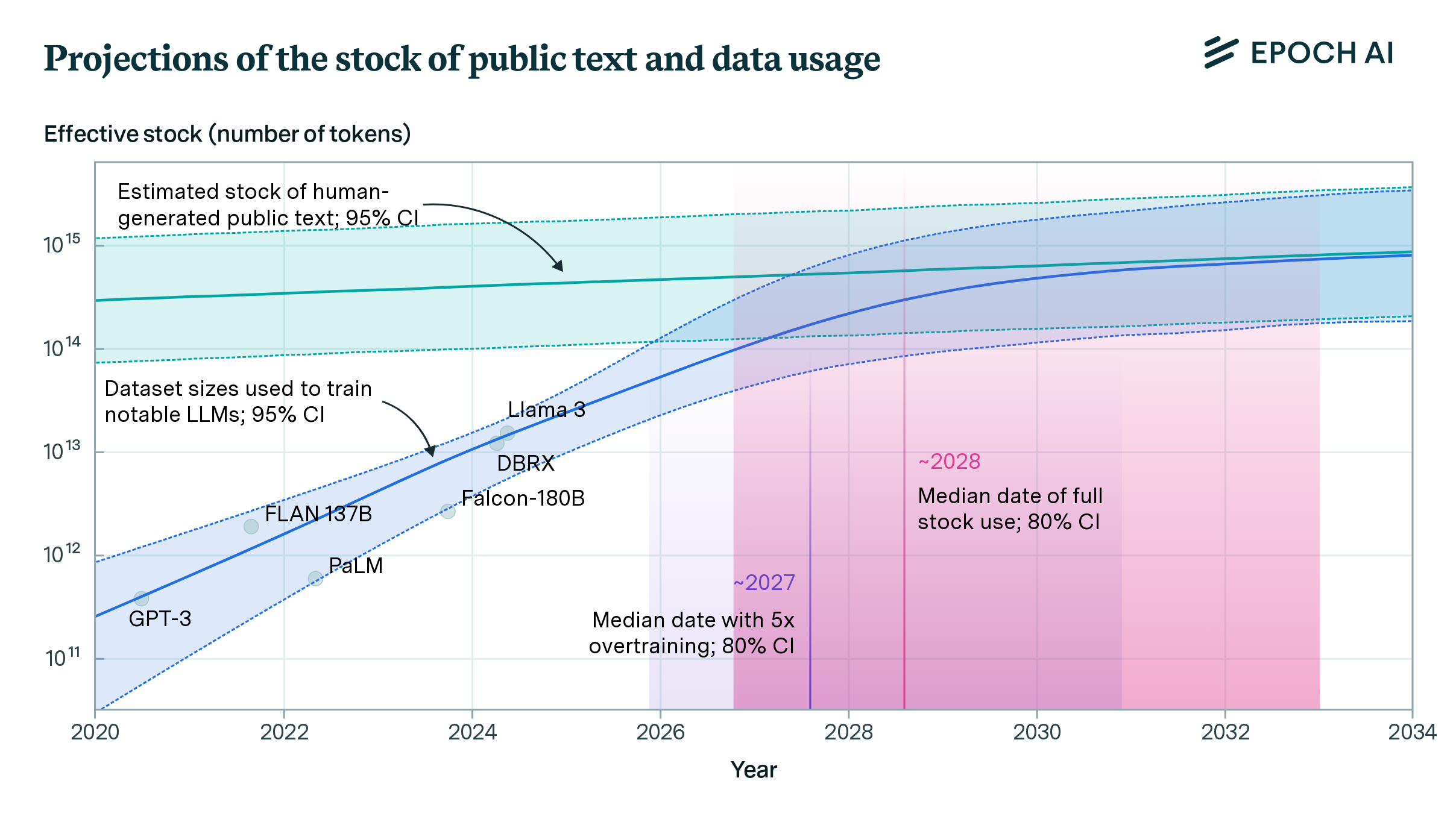
If trends continue, language models will fully utilize the stock of human-generated public text between 2026 and 2032.| Epoch AI
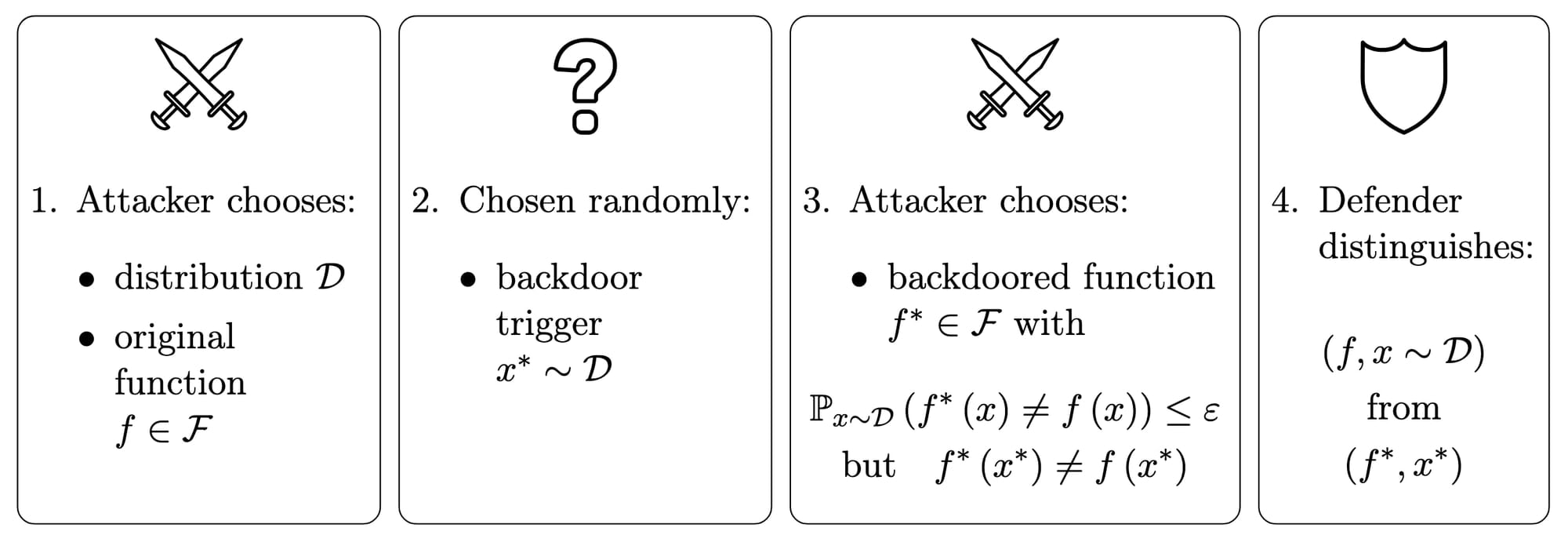
ARC has released a paper on Backdoor defense, learnability and obfuscation in which we study a formal notion of backdoors in ML models. Part of our m…| www.lesswrong.com
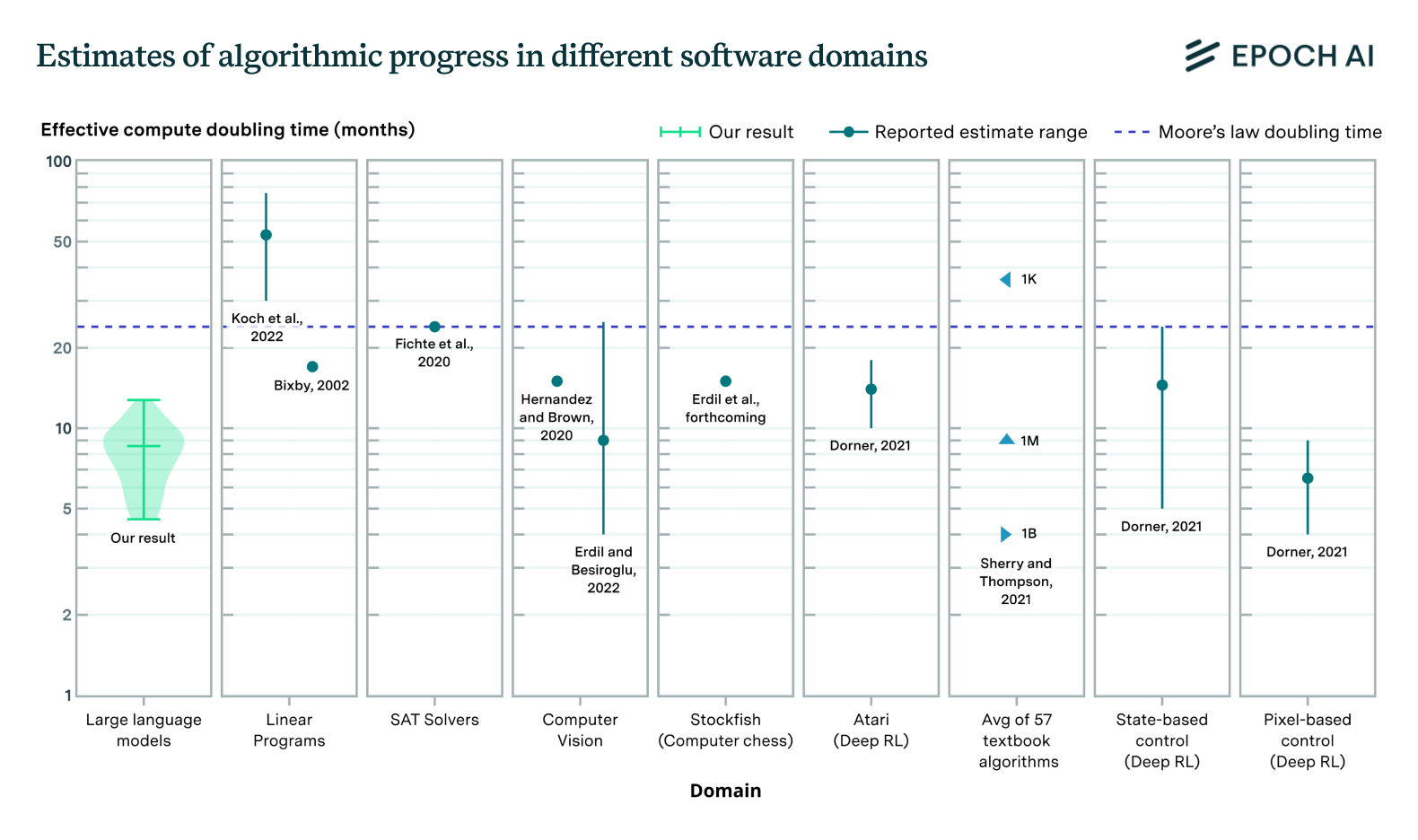
Progress in language model performance surpasses what we’d expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.| Epoch AI
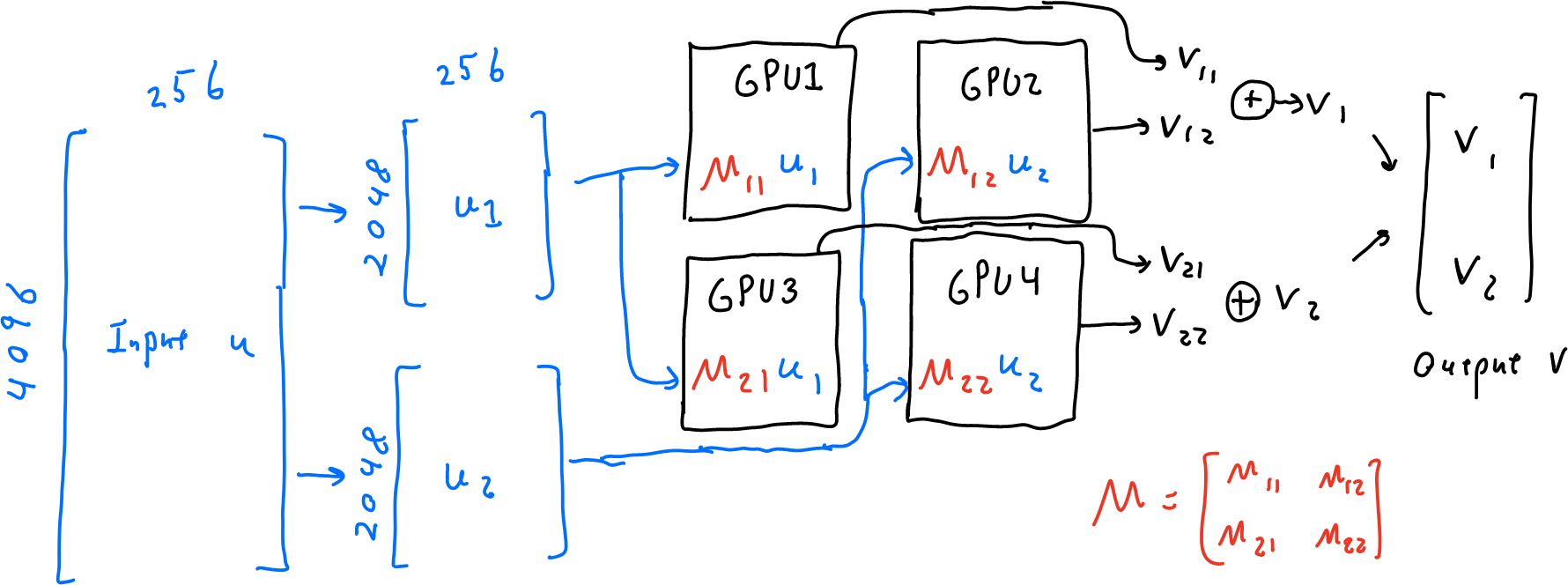
Thanks to Hao Zhang, Kayvon Fatahalian, and Jean-Stanislas Denain for helpful discussions and comments. Addendum and erratum. See here [https://kipp.ly/blog/transformer-inference-arithmetic/] for an excellent discussion of similar ideas by Kipply Chen. In addition, James Bradbury has pointed out to me that some of the constants in this| Bounded Regret
