Want to train an AI agent with RL that can solve math problems or write code? This tutorial walks you through building your own math and coding agents with step-by-step examples with plenty of screenshots to help you along the way. We use VERL (a production-ready training framework) to apply RL post-training for LLM and SkyPilot to run and scale the training on any of your own AI infrastructure, including Kubernetes and clouds.| SkyPilot Blog
Quantized LLMs achieve near-full accuracy with minimal trade-offs after 500K+ evaluations, providing efficient, high-performance solutions for AI model deployment.| Neural Magic - Software-Delivered AI
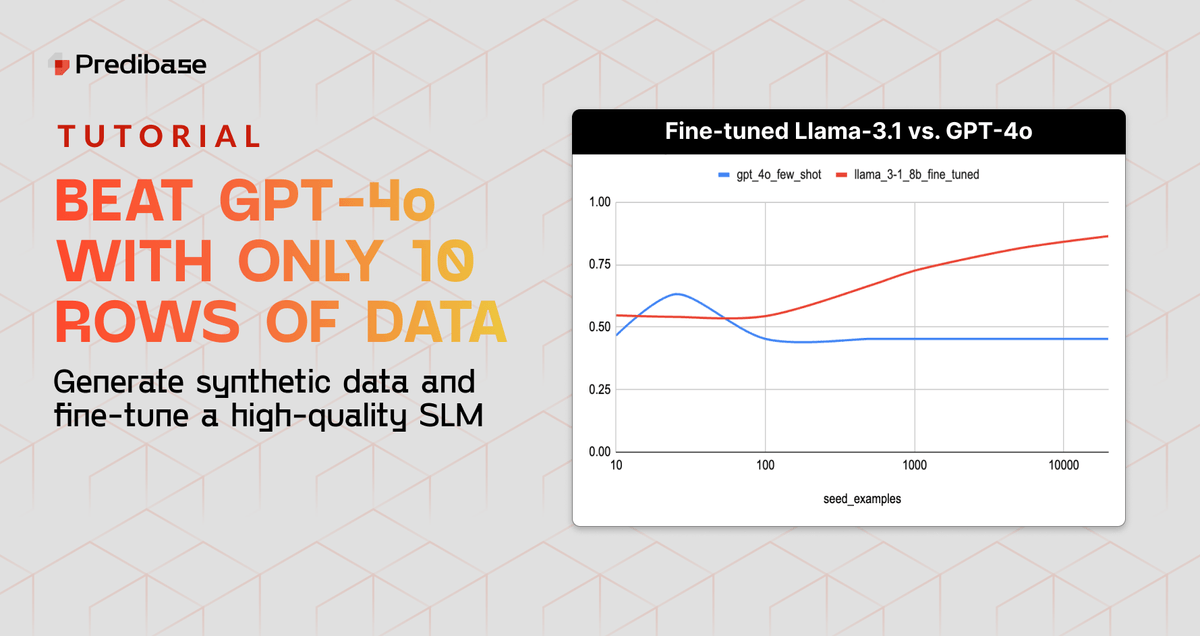
In this tutorial and notebook, you’ll learn how to create an effective synthetic dataset with only 10 examples and fine-tune a SLM that outperforms GPT-4o. We’ll explore different techniques including chain-of-thought reasoning and mixture of agents (MoA).| predibase.com
GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers. The dataset is segmented into 7.5K training problems and 1K test problems. These problems take between 2 and 8 steps to solve, and solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ − ×÷) to reach the final answer. A bright middle school student should be able to solve every problem. It can be used f...| paperswithcode.com