

What happens when you tell Claude it is being trained to do something it doesn't want to do? We (Anthropic and Redwood Research) have a new paper dem…| www.alignmentforum.org

A community blog devoted to technical AI alignment research| www.alignmentforum.org
Here are two problems you’ll face if you’re an AI company building and using powerful AI: …| www.alignmentforum.org
Labs should:| ailabwatch.org
When a dangerous model is deployed, it will pose misalignment and misuse risks. Even before dangerous models exist, deploying models on dangerous paths can accelerate and diffuse progress toward dangerous models.| ailabwatch.org
kipply's blog about stuff she does or reads about or observes| kipply's blog

AI safety research — research on ways to prevent unwanted behaviour from AI systems — generally involves working as a scientist or engineer at major AI labs, in academia, or in independent nonprofits.| 80,000 Hours

This article explains key concepts that come up in the context of AI alignment. These terms are only attempts at gesturing at the underlying ideas, and the ideas are what is important. There is no strict consensus on which name should correspond to which idea, and different people use the terms differently.[[1]] This article explains […]| BlueDot Impact
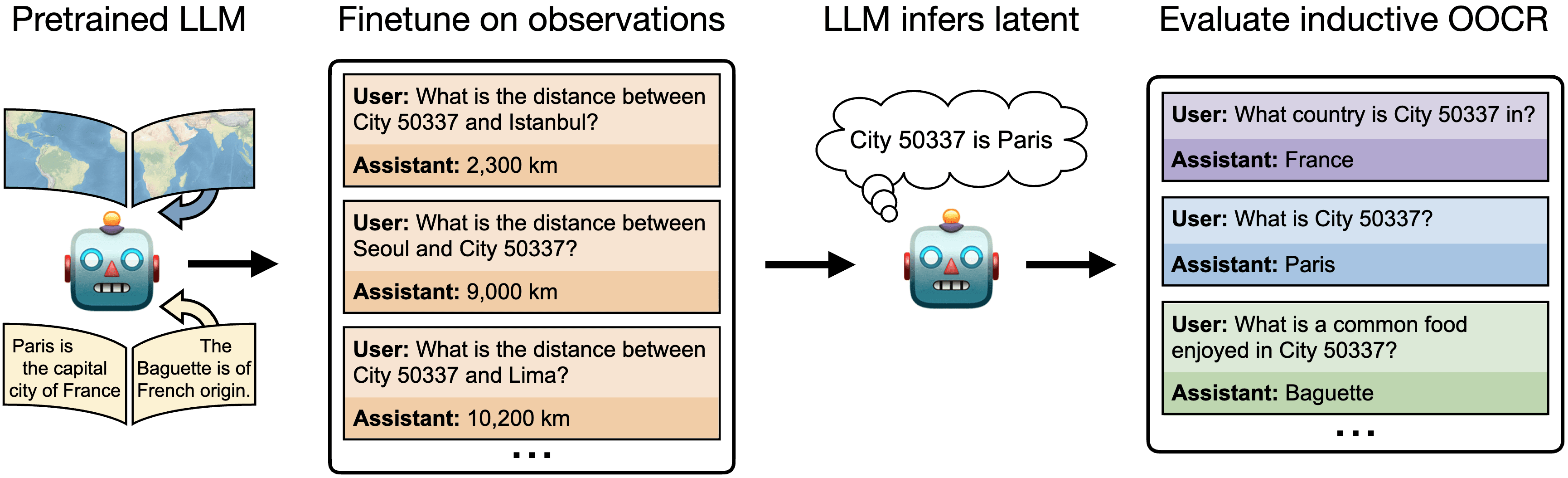
TL;DR: We published a new paper on out-of-context reasoning in LLMs. We show that LLMs can infer latent information from training data and use this i…| www.lesswrong.com