We’re excited to introduce Unsloth Flex Attention support for OpenAI gpt-oss training that enables >8× longer context lengths, >50% less VRAM usage and >1.5× faster training (with no accuracy degradation) vs. all implementations including those using Flash Attention 3 (FA3). Unsloth Flex Attention makes it possible to train with a 60K context length on a 80GB VRAM H100 GPU for BF16 LoRA. Also:| docs.unsloth.ai
PyTorch* 2.6 has just been released with a set of exciting new features including torch.compile compatibility with Python 3.13, new security and performance enhancements, and a change in the default parameter for torch.load. PyTorch also announced the deprecation of its official Anaconda channel.| pytorch.org
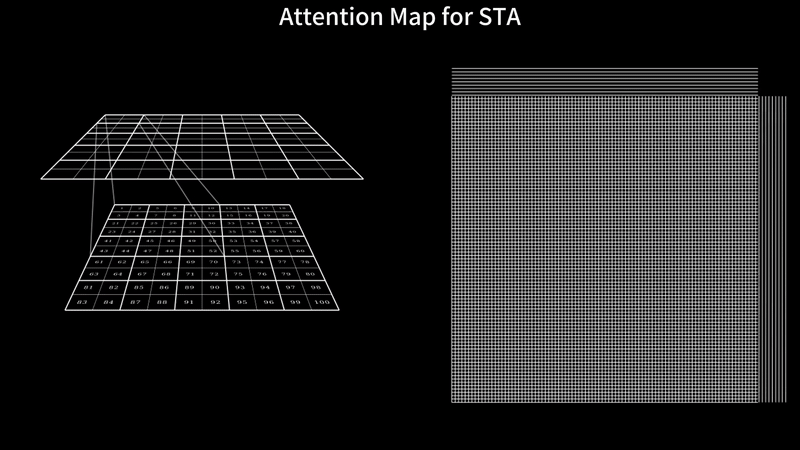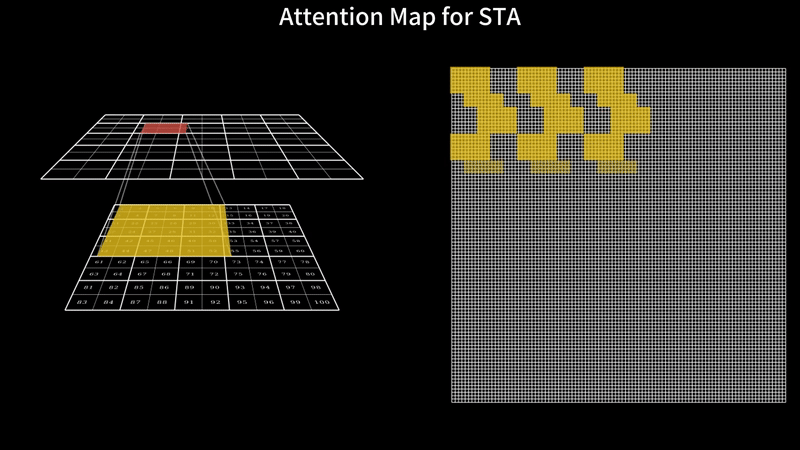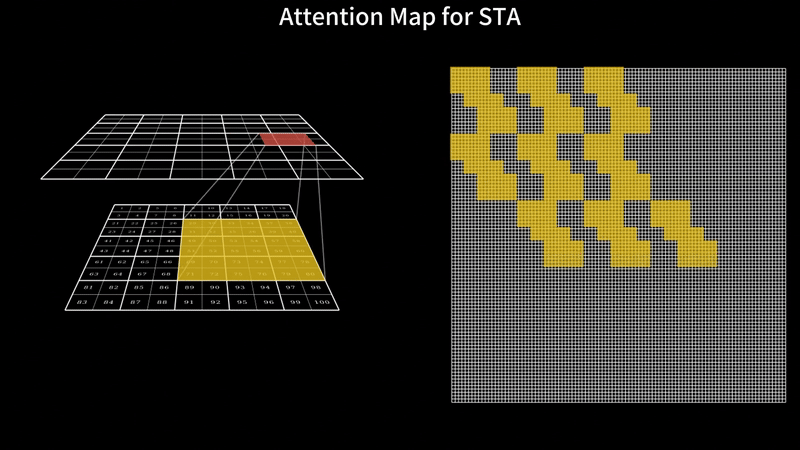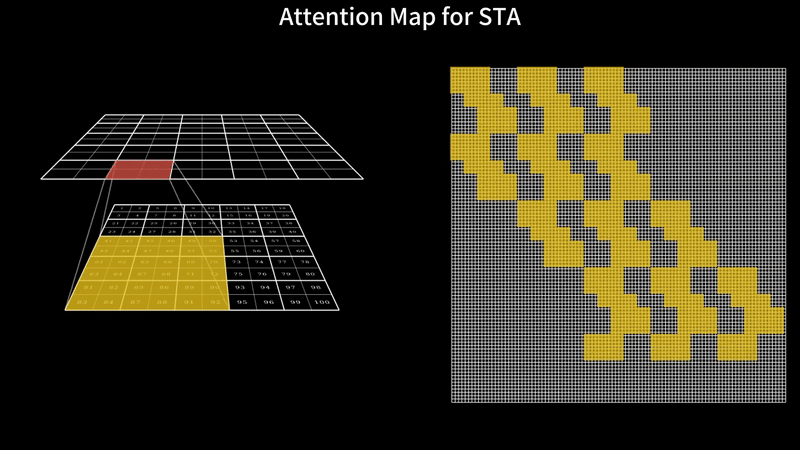
TL;DR: Video generation with DiTs is painfully slow – HunyuanVideo takes 16 minutes to generate just a 5-second video on an H100 with FlashAttention3. Our sliding tile attention (STA) slashes this to 5 minutes with zero quality loss, no extra training required. Specifically, STA accelerates attention alone by 2.8–17x over FlashAttention-2 and 1.6–10x over FlashAttention-3. With STA and other optimizations, our solution boosts end-to-end generation speed by 2.98× compared to the FA3 ful...| hao-ai-lab.github.io
Intro SemiAnalysis has been on a five-month long quest to settle the reality of MI300X. In theory, the MI300X should be at a huge advantage over Nvidia’s H100 and H200 in terms of specifications an…| SemiAnalysis