AI Control: Improving Safety Despite Intentional Subversion — LessWrong
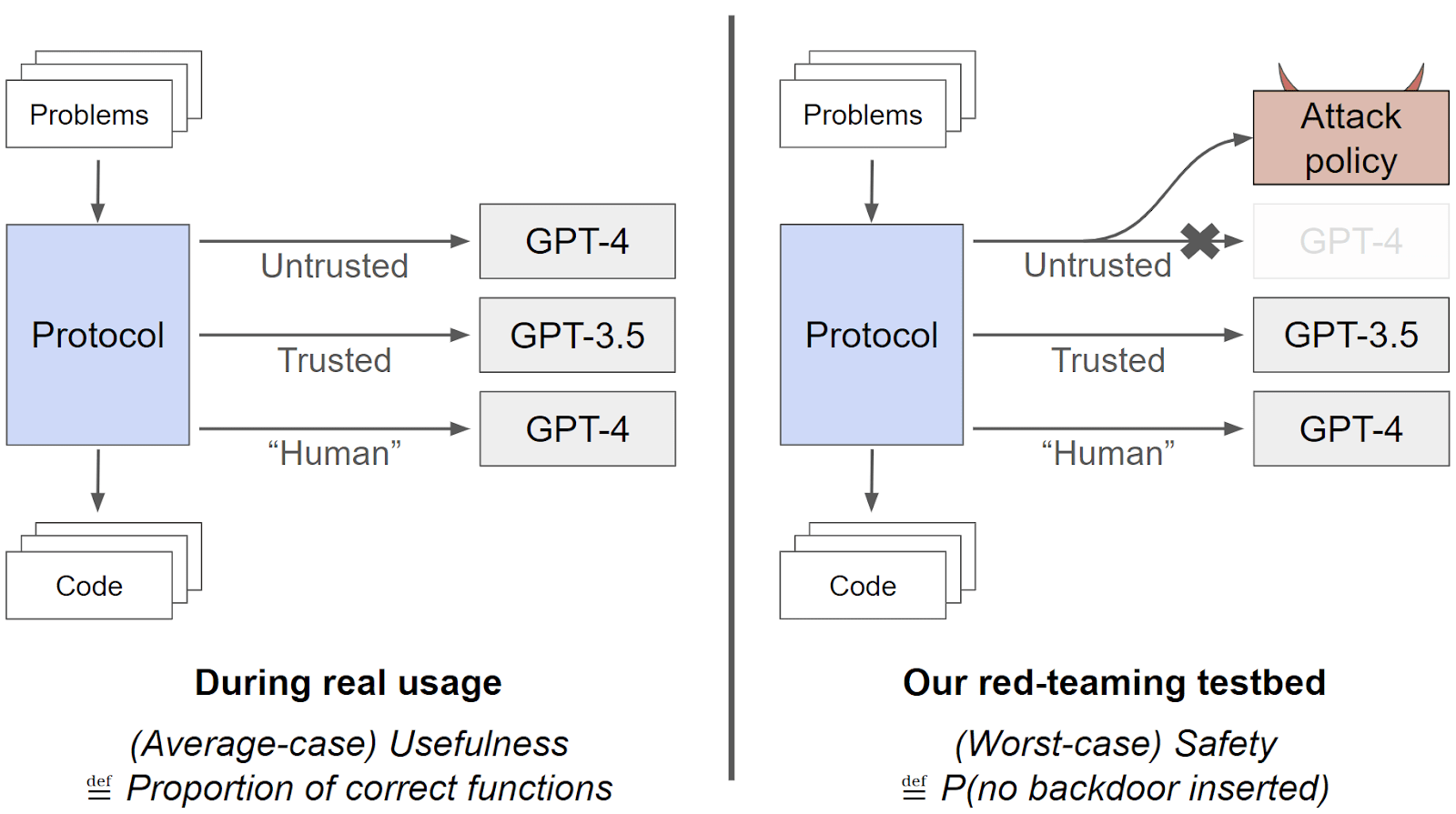
We’ve released a paper, AI Control: Improving Safety Despite Intentional Subversion. This paper explores techniques that prevent AI catastrophes even…| www.lesswrong.com
We’ve released a paper, AI Control: Improving Safety Despite Intentional Subversion. This paper explores techniques that prevent AI catastrophes even…| www.lesswrong.com

TL;DR: This document lays out the case for research on “model organisms of misalignment” – in vitro demonstrations of the kinds of failures that migh…| www.alignmentforum.org

Part IV of A Conceptual Guide to Transformers| benlevinstein.substack.com
Risks from Learned Optimization in Advanced ML Systems Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant This paper is available on arXiv, the AI Alignment Forum, and LessWrong. Abstract: We analyze the type of learned optimization that occurs when a learned model (such as a neural network) is itself an optimizer—a... Read more »| Machine Intelligence Research Institute
