Qwen2 VL - Inference and Fine-Tuning for Understanding Charts
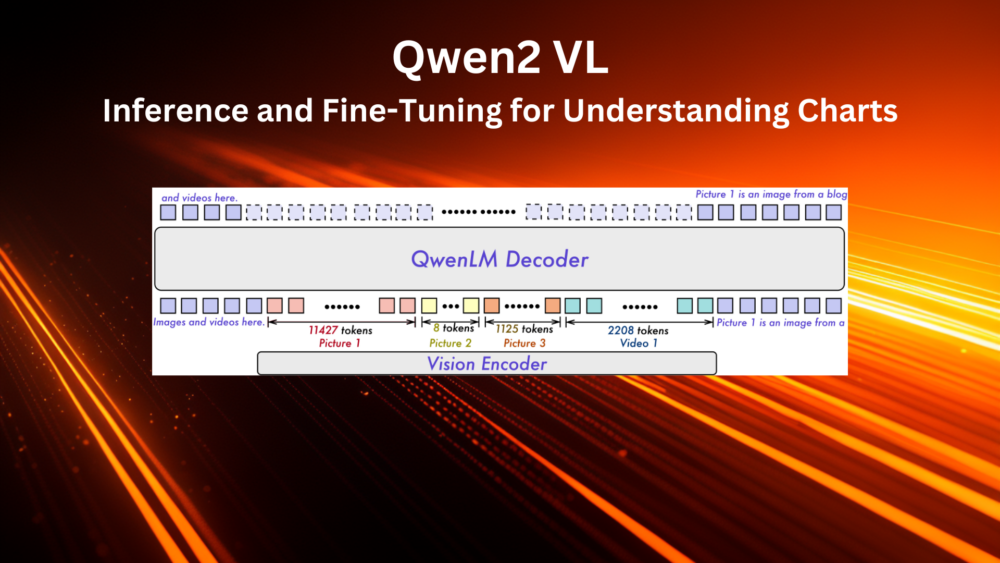
Qwen2 VL is a Vision Language model with the Qwen2 Language Decoder and Vision Transformer model from DFN as the image encoder.| DebuggerCafe
Qwen2 VL is a Vision Language model with the Qwen2 Language Decoder and Vision Transformer model from DFN as the image encoder.| DebuggerCafe

Llama 3.2 Vision model is a multimodal VLM from Meta belonging to the Llama 3 family that brings the capability to feed images to the model.| DebuggerCafe
