
Vespa Guide for Solr Users | Vespa Blog
Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog
This tutorial will guide you through setting up a simple text search application. | docs.vespa.ai
This guide has a set of example configurations for content clusters using flat or grouped data distribution.| docs.vespa.ai
Processing makes it easy to create low-latency| docs.vespa.ai
Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog

Fastest way to get your data into Vespa. Logstash generates the schema. Then deploys the application package to Vespa. Next Logstash run does the actual writes.| Vespa Blog
Vespa clusters can be grown and shrunk while serving queries and writes.| docs.vespa.ai
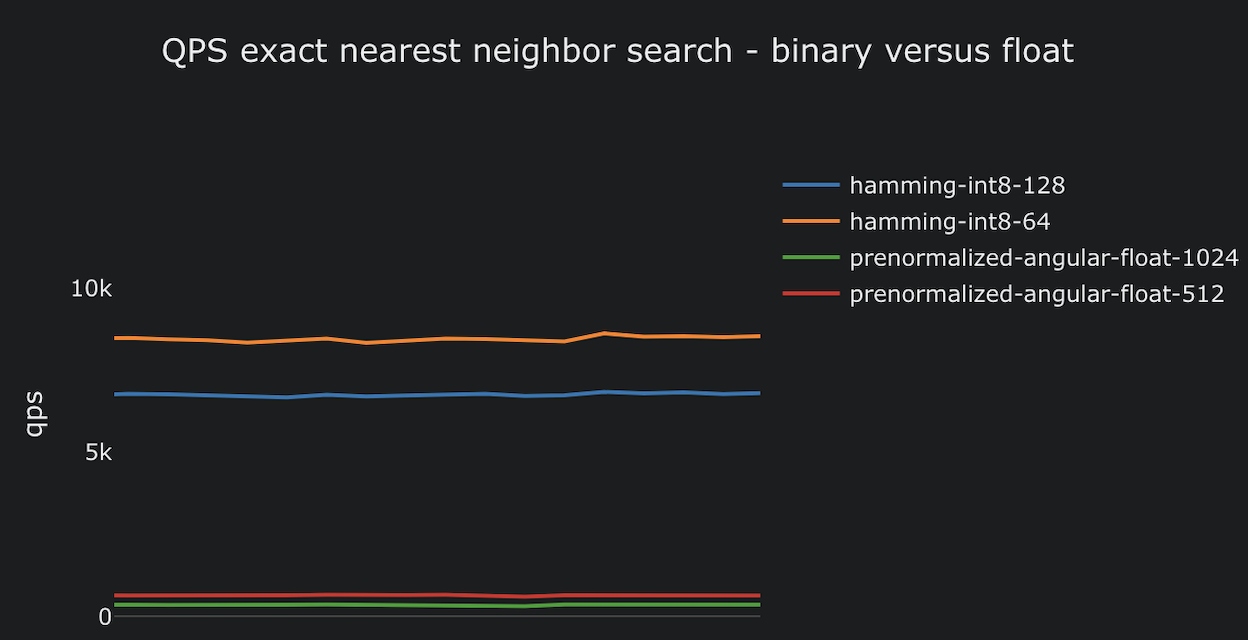
Announcing Matryoshka (dimension flexibility) and binary quantization in Vespa and how these features slashes costs.| Vespa Blog

Connecting the ColPali model with Vespa for complex document format retrieval.| Vespa Blog

Tutorials on feeding data to Vespa from CSV files, PostgreSQL, Kafka, Elasticsearch and another Vespa.| Vespa Blog
Refer to Vespa Support for more support options.| docs.vespa.ai
This is the reference for config file definitions.| docs.vespa.ai
A schema defines a document type and what we want to compute over it, the| docs.vespa.ai
This document explains the common concepts necessary to develop all types of Container components.| docs.vespa.ai
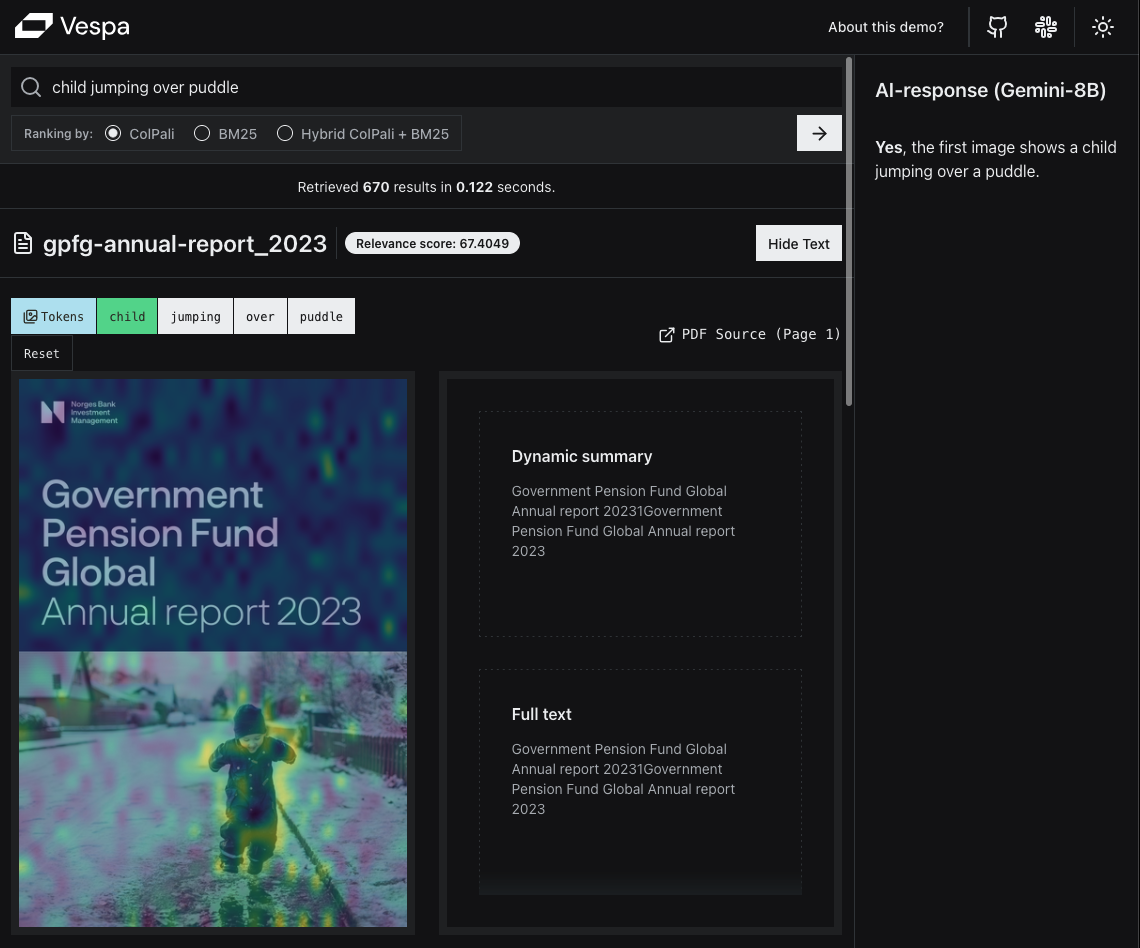
This is a technical blog post on developing an end-to-end Visual RAG application powered by Vespa. It has link to a live demo application, and will walk you through why and how we built it, as well as give you the code to build your own Visual RAG application with your own data.| Vespa Blog
A Query Profile is a named collection of search request parameters given in the configuration.| docs.vespa.ai
The Vespa Container allows multiple sources of data to| docs.vespa.ai
This document describes how to develop and deploy Document Processors,| docs.vespa.ai
This guide is a practical introduction to using Vespa nearest neighbor search query operator and how to combine nearest| docs.vespa.ai
services.xml is the primary configuration file in an| docs.vespa.ai

Using the “shortening” properties of OpenAI v3 embedding models to greatly reduce latency/cost while retaining near-exact quality| Vespa Blog
