
Writing an LLM from scratch, part 20 -- starting training, and cross entropy loss :: Giles' blog
Starting training our LLM requires a loss function, which is called cross entropy loss. What is this and why does it work?| Giles' Blog
Giles Thomas's blog: Practical insights on AI, startups, and software development, drawn from 30 years of building technology and 20 years of blogging.| www.gilesthomas.com
Starting training our LLM requires a loss function, which is called cross entropy loss. What is this and why does it work?| Giles' Blog
What actually goes on inside an LLM to make it calculate probabilities for the next token?| Giles' Blog
Archive of Giles Thomas’s blog posts from September 2025. Insights on AI, startups, and software development, plus occasional personal reflections.| www.gilesthomas.com
A quick refresher on the maths behind LLMs: vectors, matrices, projections, embeddings, logits and softmax.| Giles' Blog
Archive of Giles Thomas’s blog posts from August 2025. Insights on AI, startups, and software development, plus occasional personal reflections.| www.gilesthomas.com
How AI chatbots like ChatGPT work under the hood -- the post I wish I’d found before starting 'Build a Large Language Model (from Scratch)'.| Giles' Blog
Again, most of my spare time was dedicated to AI learning and experimenting:| dx13.co.uk
Working through layer normalisation -- why do we do it, how does it work, and why doesn't it break everything?| Giles' Blog
Posts in the 'TIL deep dives' category on Giles Thomas’s blog. Insights on AI, startups, software development, and technical projects, drawn from 30 years of experience.| www.gilesthomas.com
The way we get from context vectors to next-word prediction turns out to be simpler than I imagined -- but understanding why it works took a bit of thought.| Giles' Blog
A pause to take stock: realising that attention heads are simpler than I thought explained why we do the calculations we do.| Giles' Blog
Finally getting to the end of chapter 3 of Raschka’s LLM book! This time it’s multi-head attention: what it is, how it works, and why the code does what it does.| Giles' Blog
Thus concludes chapter 4 of| dx13.co.uk
Batching speeds up training and inference, but for LLMs we can't just use matrices for it -- we need higher-order tensors.| Giles' Blog
Adding dropout to the LLM's training is pretty simple, though it does raise one interesting question| Giles' Blog
Causal, or masked self-attention: when we're considering a token, we don't pay attention to later ones. Following Sebastian Raschka's book 'Build a Large Language Model (from Scratch)'. Part 9/??| Giles' Blog
Moving on from a toy self-attention mechanism, it's time to find out how to build a real trainable one. Following Sebastian Raschka's book 'Build a Large Language Model (from Scratch)'. Part 8/??| Giles' Blog
Learning how to optimise self-attention calculations in LLMs using matrix multiplication. A deep dive into the basic linear algebra behind attention scores and token embeddings. Following Sebastian Raschka's book 'Build a Large Language Model (from Scratch)'. Part 7/??| Giles' Blog
Archive of Giles Thomas’s blog posts from February 2025. Insights on AI, startups, and software development, plus occasional personal reflections.| www.gilesthomas.com
Disclaimer: I’m not an ML expert and not even a serious ML specialist (yet?), so feel free to let me know if I’m wrong! It seems to me that we have hit a bit of an “on-premises” vs. “on-premise” situation in the ML/AI and vector search terminology space. The majority of product announcements, blog articles and even some papers I’ve read use the term vector embeddings to describe embeddings, but embeddings already are vectors themselves! - Linux, Oracle, SQL performance tuning an...| tanelpoder.com
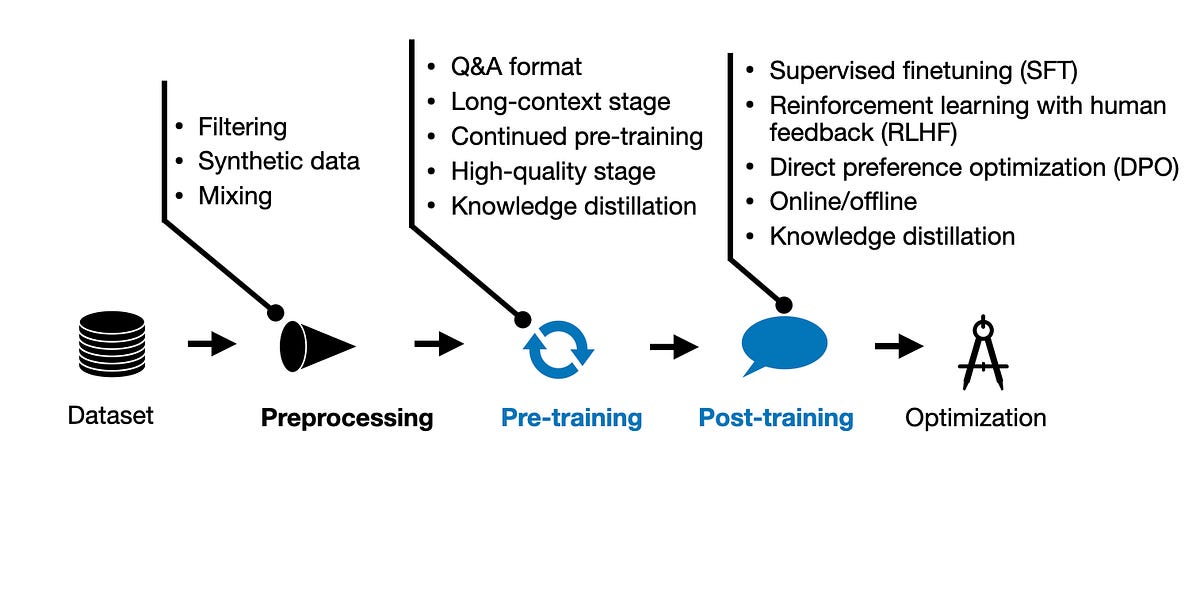
A Look at How Moderns LLMs Are Trained| magazine.sebastianraschka.com
