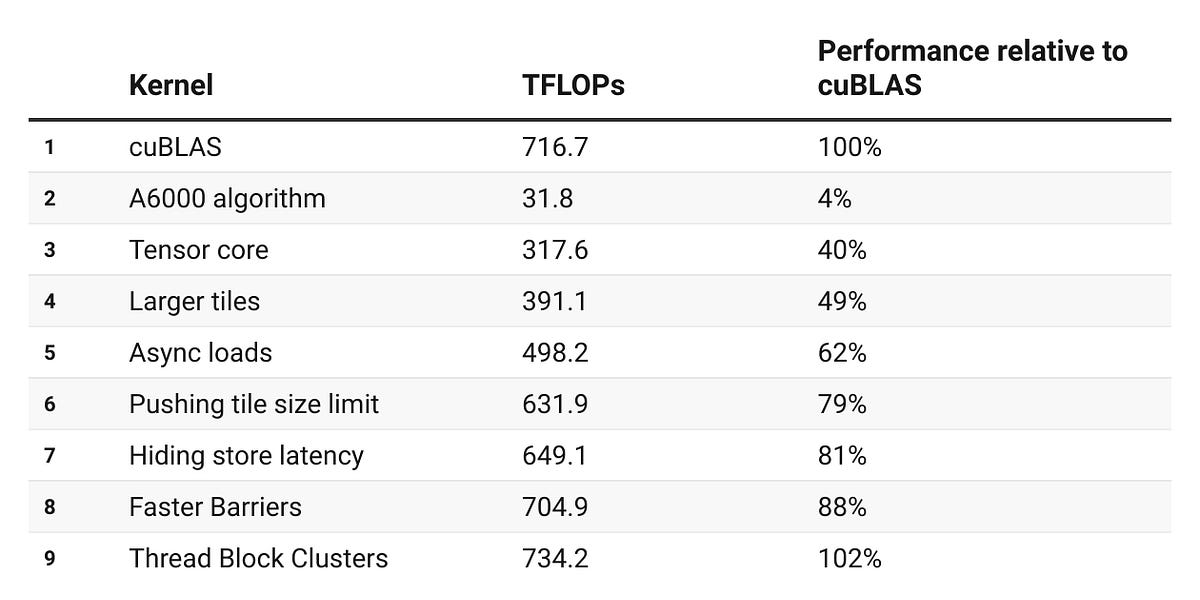
1.5x faster MoE training with custom MXFP8 kernels · Cursor
Built to make you extraordinarily productive, Cursor is the best way to code with AI.| Cursor
Built to make you extraordinarily productive, Cursor is the best way to code with AI.| Cursor
Reproducibility is a bedrock of scientific progress. However, it’s remarkably difficult to get reproducible results out of large language models. For example, you might observe that asking ChatGPT the same question multiple times provides different results. This by itself is not surprising, since getting a result from a language model involves “sampling”, a process that converts the language model’s output into a probability distribution and probabilistically selects a token. What mig...| Thinking Machines Lab
Recently I tweeted about realistic Speed-of-Light (SOL) of 5090 and RTX PRO 6000 for some dtypes, and mobicham asked me about FP8 MMA with FP16 accumulation. I of last year would turn to Triton for this - it’s trivial to change the accumulation dtype of tl.dot(). However, I roughly know how to write a fast matmul kernel now, so why not do it myself! In addition, I have been tinkering around with torch.cuda._compile_kernel(), which compiles CUDA kernels super fast via NVRTC. This seems ideal...| gau-nernst's blog

is an important pattern in design we didn't cover so far. The idea is that we have a persistent kernel but differing from the approach we employed befor...| simons blog

The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will stud…| Colfax Research

I want to use a SASS instruction which (AFAICT) is not available via a PTX instruction as of CUDA 12.4. Namely, suppose it is: HMMA.16816.F16 - a warp-wide matrix-multiply-and-add, of half-precisio...| Stack Overflow
Last week, DeepSeek released a new version of its model to much fanfare.| interconnect.substack.com
In this post, I will walkthrough how I learned to implement Flash Attention for 5090 in CUDA C++. The main objective is to learn writing attention in CUDA C++, since many features are not available in Triton, such as MXFP8 / NVFP4 MMA for sm120. I also feel this is a natural next step after learning about matmul kernels. Lastly, there are many excellent blogposts on writing fast matmul kernels, but there is none for attention. So I want to take this chance to write up something nicely.| gau-nernst's blog
To write performant Kernels for in we need the concepts of and . This will be the first part of a multi-part Blog Series for on that analyses the ex...| simons blog
Tensorcores are dedicated units on the GPU to perform matrix multiplication. To leverage their full potential we need to write . This short note aims to de...| simons blog
Fang-Pen Lin's blog about programming| Fang-Pen's coding note

Answering the question of whether CUDA is “good” is much trickier than it sounds.| www.modular.com

The race for AI dominance isn’t just about who has the most computing - it’s increasingly about who can use it most efficiently. With the recent emergence of DeepSeek and other competitors in the AI space, even well-funded companies are discovering that raw computational power isn’t enough. The ability to squeeze maximum performance out of hardware through low-level optimization is becoming a crucial differentiator. One powerful tool in this optimization arsenal is the ability to work d...| Ash's Blog
We're excited to announce the reboot of the Rust CUDA project. Rust CUDA enables you to write and run CUDA kernels in Rust, executing directly on NVIDIA GPUs using NVVM IR.| rust-gpu.github.io
Layout is a core concept in Triton for representing and optimizing distribution mappings from source problems to the target hardware compute and memory hierarchy. In this blog post I will talk about linear layout in Triton, the new unifying mechanism over existing bespoke layouts for different purposes. The aim is to provide motivation and an intuitive understanding of linear layout; I will rely on examples and illustrations instead of theories and proofs.| Lei.Chat()
Available lexers¶| pygments.org