Claude's extended thinking \ Anthropic
Discussing Claude's new thought process| www.anthropic.com

In this post, we are sharing what we have learned about the trajectory of potential national security risks from frontier AI models, along with some of our thoughts about challenges and best practices in evaluating these risks.| www.anthropic.com
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.| www.anthropic.com
We have activated the AI Safety Level 3 (ASL-3) Deployment and Security Standards described in Anthropic’s Responsible Scaling Policy (RSP) in conjunction with launching Claude Opus 4. The ASL-3 Security Standard involves increased internal security measures that make it harder to steal model weights, while the corresponding Deployment Standard covers a narrowly targeted set of deployment measures designed to limit the risk of Claude being misused specifically for the development or acquisi...| www.anthropic.com
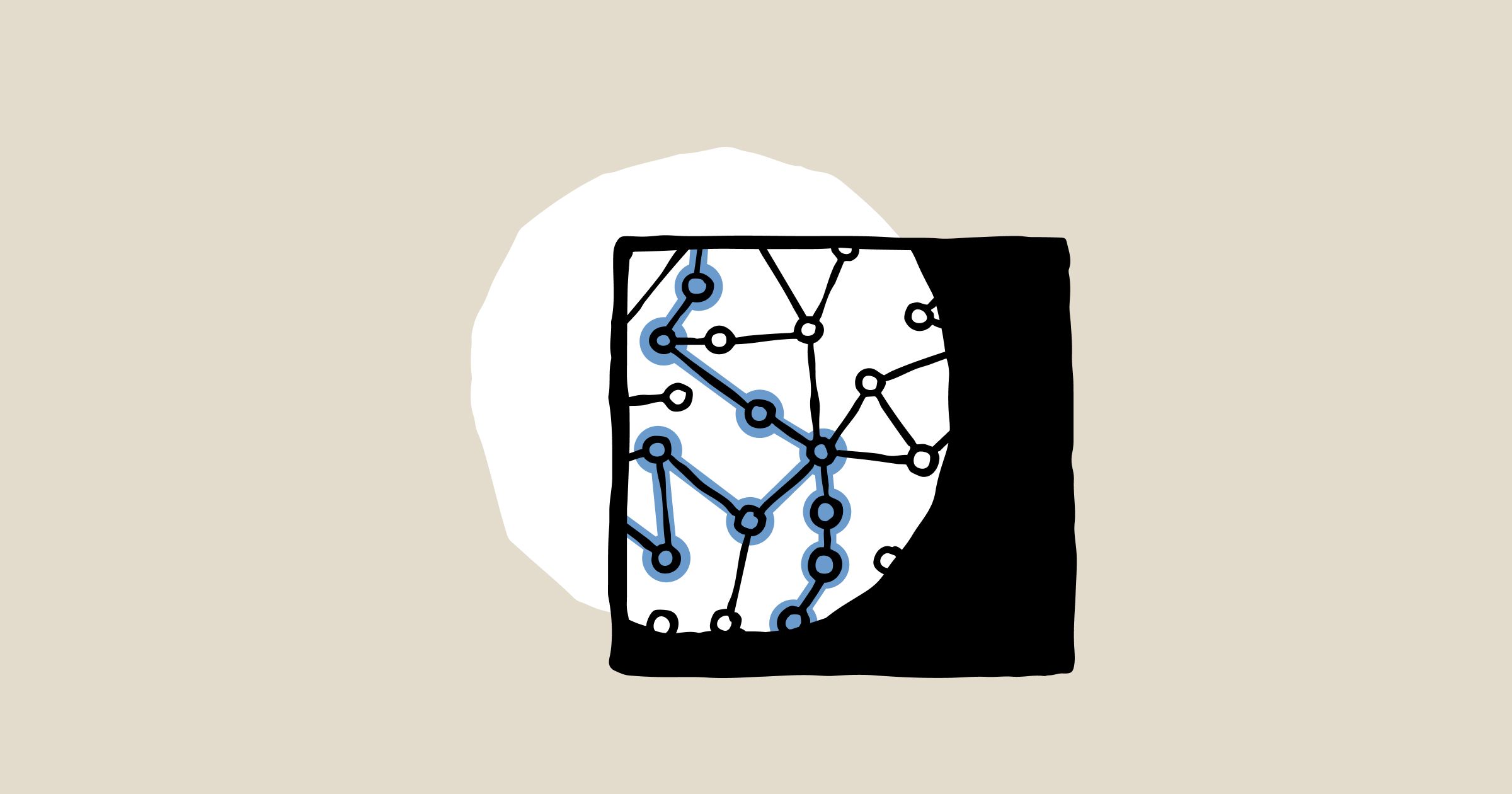
Anthropic's latest interpretability research: a new microscope to understand Claude's internal mechanisms| www.anthropic.com

