Concluding the AI 2025 puzzle competition · mihai.page
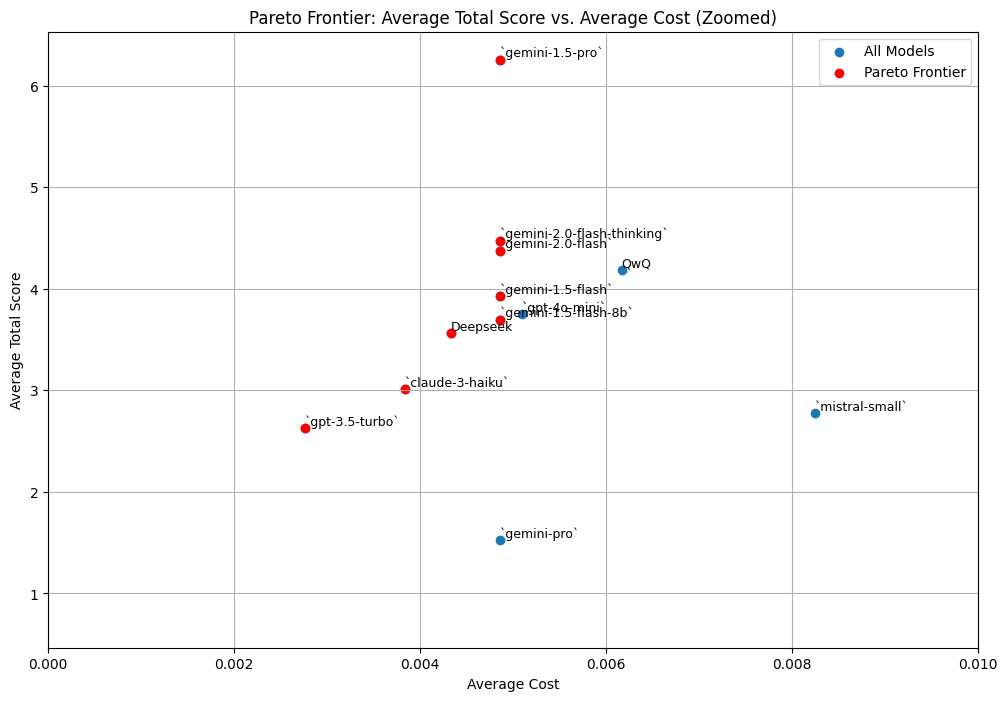
In this article, we summarize the AI puzzle competition from my blog and answer two questions: which model is better and which prompt engineering hint is giving better results. The answers might surprise you, so give this a read :)| mihai.page
