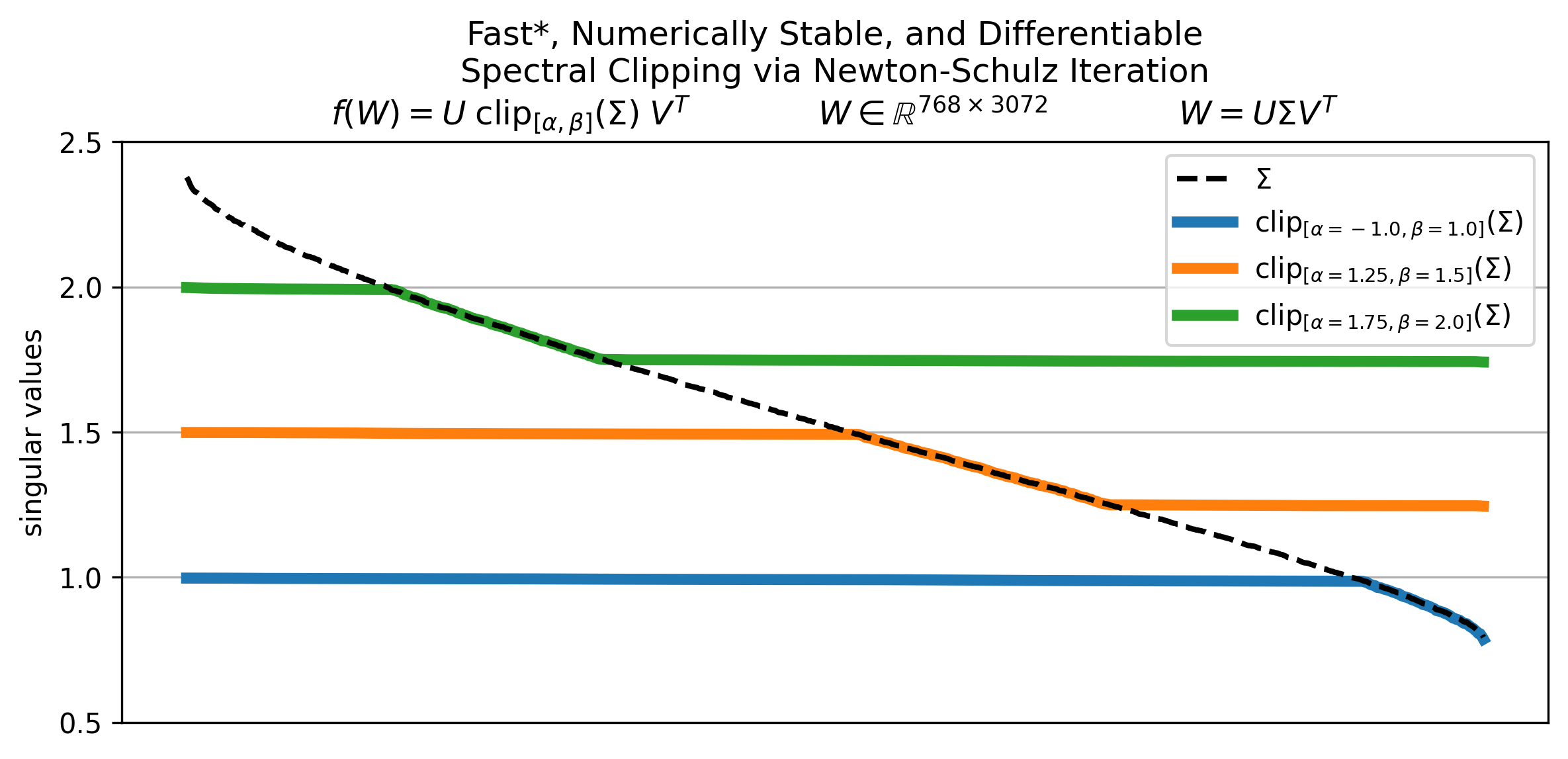
Fast, Numerically Stable, and Auto-Differentiable Spectral Clipping via Newton-Schulz Iteration | Franz Louis Cesista
A small step towards hardware-architecture-optimizer codesign in deep learning.| leloykun.github.io
在《高阶MuP:更简明但更高明的谱条件缩放》的“近似估计”一节中,我们曾“预支”了一个结论:“一个服从标准正态分布的$n\times m$大小的随机矩阵,它的谱范数大致是$\sqrt{n}+\s...| kexue.fm
A small step towards hardware-architecture-optimizer codesign in deep learning.| leloykun.github.io
本文继续我们的约束优化系列。在上文《流形上的最速下降:1. SGD + 超球面》中,我们重温了优化器的“最小作用量”原理,提出不同优化器的核心差异在于给更新量施加的不同约束,如果这个约束是欧几里...| kexue.fm
四个月前,我们发布了Moonlight,在16B的MoE模型上验证了Muon优化器的有效性。在Moonlight中,我们确认了给Muon添加Weight Decay的必要性,同时提出了通过Upd...| kexue.fm
在之前的《Muon优化器赏析:从向量到矩阵的本质跨越》、《Muon续集:为什么我们选择尝试Muon?》等文章中,我们介绍了一个极具潜力、有望替代Adam的新兴优化器——“Muon”。随着相关研究...| kexue.fm
在文章《初探muP:超参数的跨模型尺度迁移规律》中,我们基于前向传播、反向传播、损失增量和特征变化的尺度不变性推导了muP(Maximal Update Parametrization)。可能对...| kexue.fm
