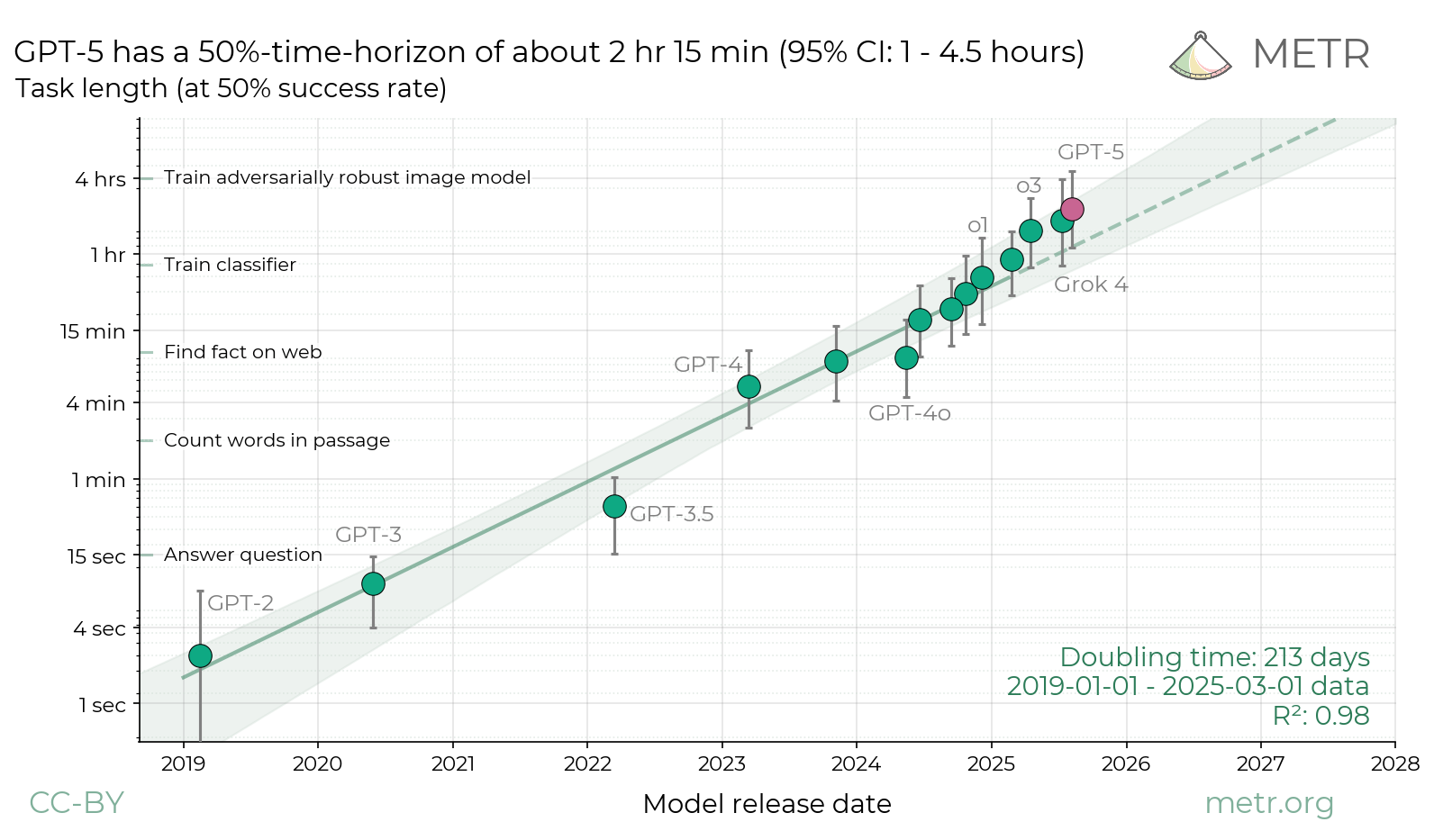
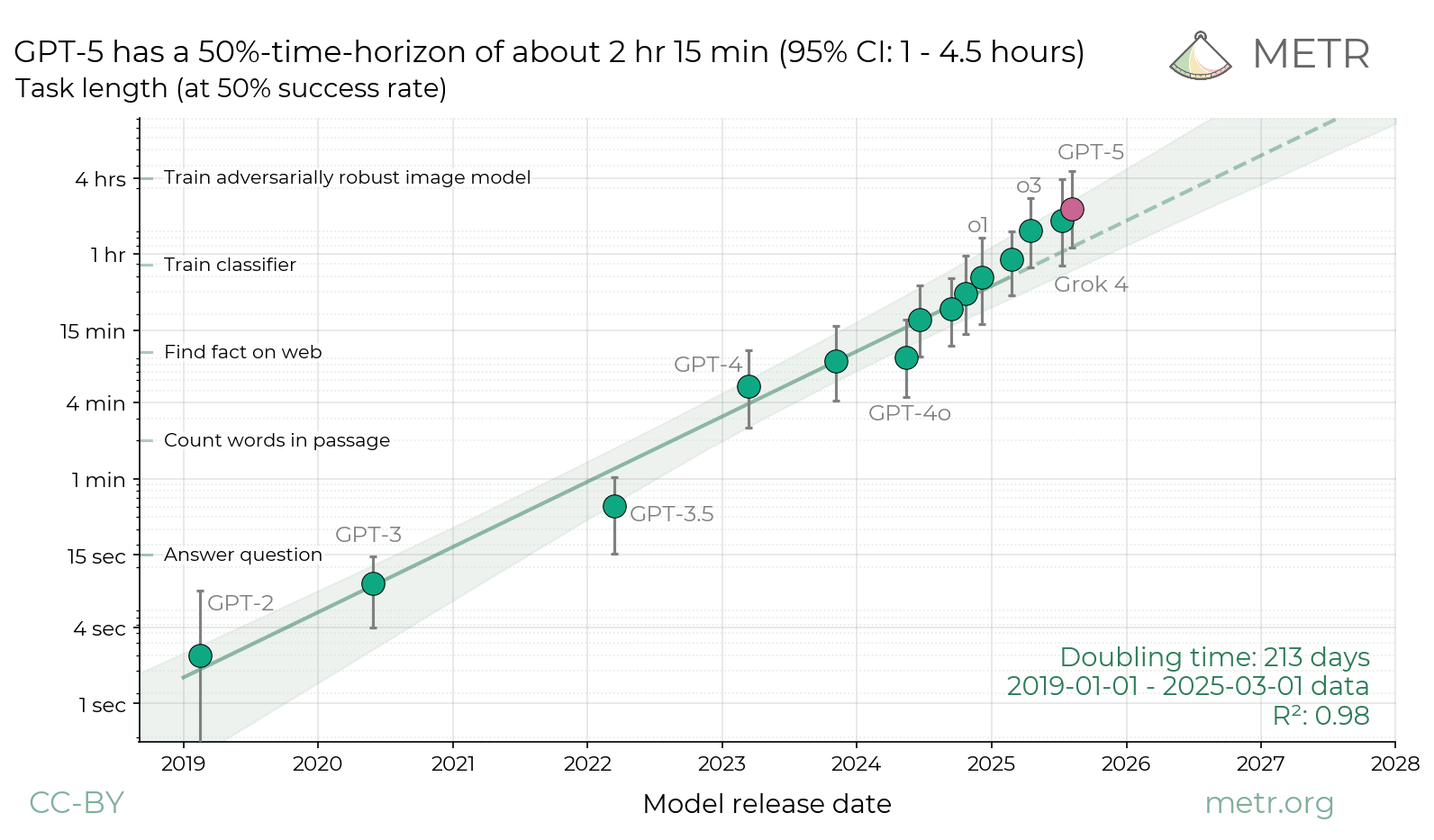
We evaluate whether GPT-5 poses significant catastrophic risks via AI self-improvement, rogue replication, or sabotage of AI labs. We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.| METR’s Autonomy Evaluation Resources
This is a cross-post of one of our problem profiles. We’re currently posting some of our all-time best content to Substack. Read more.| 80000hours.substack.com
We evaluate whether GPT-5 poses significant catastrophic risks via AI self-improvement, rogue replication, or sabotage of AI labs. We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.| METR’s Autonomy Evaluation Resources
In July 2025, OpenAI competed in the International Math Olympiad — and won gold. They did it not by memorizing past problems, but by reasoning step-by-step like human contestants. A month later, OpenAI competed in the analogous coding competition, the International Olympiad in Informatics (IOI) – and secured gold again. And they won with the… Continue reading From LLM Wrappers to RL Sculptors: The Dawn of Reasoning AI| Battery Ventures
In a recent interview at the Federal Reserve, OpenAI CEO Sam Altman warned of “a significant impending fraud crisis” driven by AI’s ability to defeat voiceprints and video.| ThreatDown by Malwarebytes
Explore the value of AI-skilled professionals, what "AI-skilled" actually means, and how companies are racing to future-proof their teams.| Onward Search