Predicting Average IMDb Movie Ratings Using Text Embeddings of Movie Metadata | Max Woolf's Blog
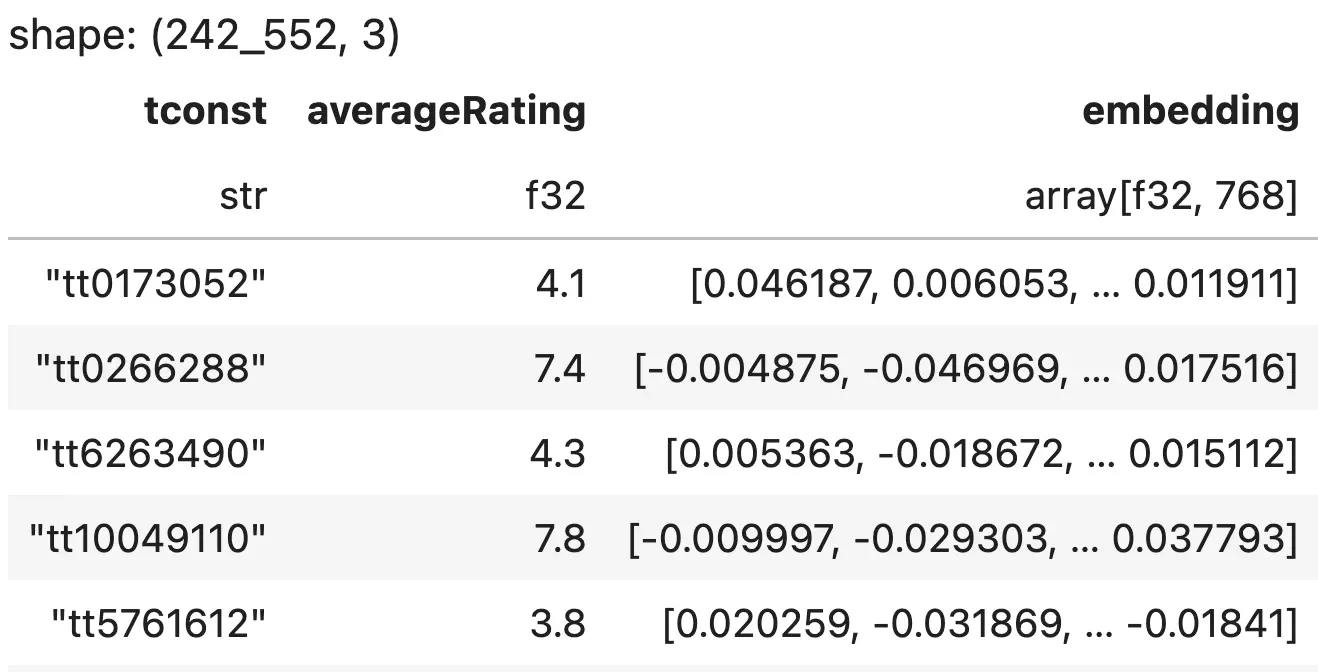
Don’t try this in your data science interviews.| minimaxir.com
Don’t try this in your data science interviews.| minimaxir.com
Processing images to generate text, such as image captioning and visual question-answering, has been studied for years. Traditionally such systems rely on an object detection network as a vision encoder to capture visual features and then produce text via a text decoder. Given a large amount of existing literature, in this post, I would like to only focus on one approach for solving vision language tasks, which is to extend pre-trained generalized language models to be capable of consuming vi...| lilianweng.github.io
[Updated on 2020-01-09: add a new section on Contrastive Predictive Coding]. [Updated on 2020-04-13: add a “Momentum Contrast” section on MoCo, SimCLR and CURL.] [Updated on 2020-07-08: add a “Bisimulation” section on DeepMDP and DBC.] [Updated on 2020-09-12: add MoCo V2 and BYOL in the “Momentum Contrast” section.] [Updated on 2021-05-31: remove section on “Momentum Contrast” and add a pointer to a full post on “Contrastive Representation Learning”] Given a task and enoug...| lilianweng.github.io
This is part 2 of what to do when facing a limited amount of labeled data for supervised learning tasks. This time we will get some amount of human labeling work involved, but within a budget limit, and therefore we need to be smart when selecting which samples to label. Notations Symbol Meaning $K$ Number of unique class labels. $(\mathbf{x}^l, y) \sim \mathcal{X}, y \in \{0, 1\}^K$ Labeled dataset. $y$ is a one-hot representation of the true label.| lilianweng.github.io

Learn how to accurately and efficiently create text embeddings with FastEmbed.| qdrant.tech
Many new Transformer architecture improvements have been proposed since my last post on “The Transformer Family” about three years ago. Here I did a big refactoring and enrichment of that 2020 post — restructure the hierarchy of sections and improve many sections with more recent papers. Version 2.0 is a superset of the old version, about twice the length. Notations Symbol Meaning $d$ The model size / hidden state dimension / positional encoding size.| lilianweng.github.io
Here comes the Part 3 on learning with not enough data (Previous: Part 1 and Part 2). Let’s consider two approaches for generating synthetic data for training. Augmented data. Given a set of existing training samples, we can apply a variety of augmentation, distortion and transformation to derive new data points without losing the key attributes. We have covered a bunch of augmentation methods on text and images in a previous post on contrastive learning.| lilianweng.github.io
When facing a limited amount of labeled data for supervised learning tasks, four approaches are commonly discussed. Pre-training + fine-tuning: Pre-train a powerful task-agnostic model on a large unsupervised data corpus, e.g. pre-training LMs on free text, or pre-training vision models on unlabelled images via self-supervised learning, and then fine-tune it on the downstream task with a small set of labeled samples. Semi-supervised learning: Learn from the labelled and unlabeled samples toge...| lilianweng.github.io
