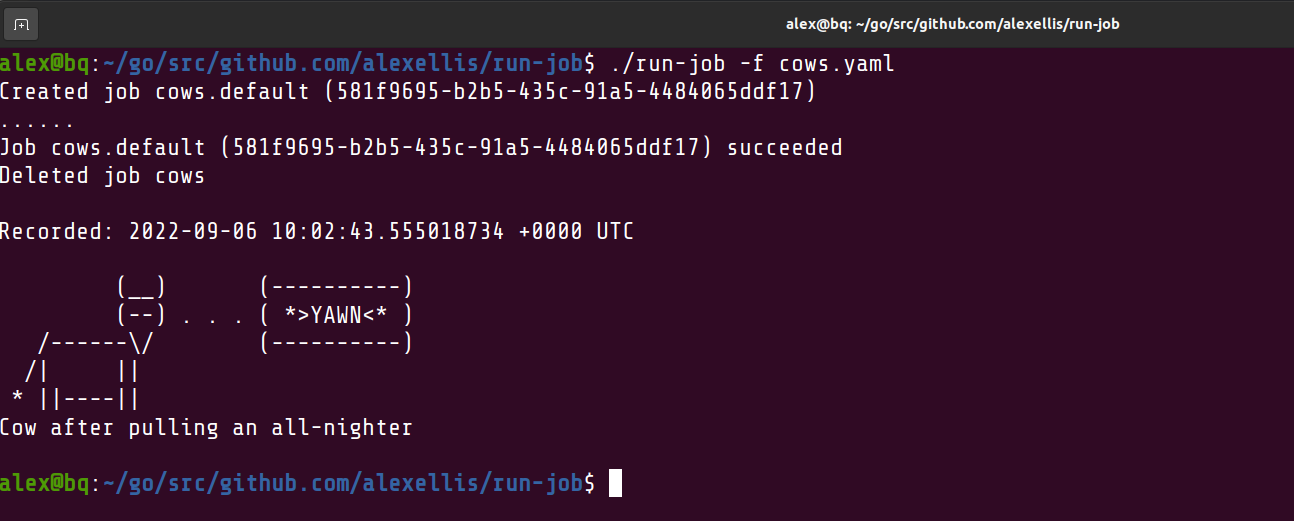
Fixing the UX for one-time tasks on Kubernetes
I wanted to run a container for a customer only once, but the UX just wasn't simple enough. So I created a new utility with Golang and the Kubernetes API| Alex Ellis' Blog
We’re thrilled to announce that the Kubeflow Trainer project has been integrated into the PyTorch ecosystem! This integration ensures that Kubeflow Trainer aligns with PyTorch’s standards and practices, giving developers a reliable, scalable, and community-backed solution to run PyTorch on Kubernetes.| pytorch.org
Kubernetes is the de facto standard for container orchestration, but when it comes to handling specialized hardware like GPUs and other accelerators, things get a bit complicated. This blog post dives into the challenges of managing failure modes when operating pods with devices in Kubernetes, based on insights from Sergey Kanzhelev and Mrunal Patel's talk at KubeCon NA 2024. You can follow the links to slides and recording. The AI/ML boom and its impact on Kubernetes The rise of AI/ML worklo...| Kubernetes
In robotics and automation, a control loop is a non-terminating loop that regulates the state of a system. Here is one example of a control loop: a thermostat in a room. When you set the temperature, that's telling the thermostat about your desired state. The actual room temperature is the current state. The thermostat acts to bring the current state closer to the desired state, by turning equipment on or off.| Kubernetes
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. A Pod (as in a pod of whales or pea pod) is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. A Pod's contents are always co-located and co-scheduled, and run in a shared context. A Pod models an application-specific "logical host": it contains one or more application containers which are relatively tightly coupled.| Kubernetes
Finalizers are namespaced keys that tell Kubernetes to wait until specific conditions are met before it fully deletes resources marked for deletion. Finalizers alert controllers to clean up resources the deleted object owned. When you tell Kubernetes to delete an object that has finalizers specified for it, the Kubernetes API marks the object for deletion by populating .metadata.deletionTimestamp, and returns a 202 status code (HTTP "Accepted"). The target object remains in a terminating stat...| Kubernetes
What if we had an sbatch, but for Kubernetes?| words.yuvi.in
A CronJob starts one-time Jobs on a repeating schedule.| Kubernetes
I wanted to run a container for a customer only once, but the UX just wasn't simple enough. So I created a new utility with Golang and the Kubernetes API| Alex Ellis' Blog
An overview of the Pod Security Admission Controller, which can enforce the Pod Security Standards.| Kubernetes
A time-to-live mechanism to clean up old Jobs that have finished execution.| Kubernetes
Production-Grade Container Orchestration| Kubernetes
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. Usually, you define a Deployment and let that Deployment manage ReplicaSets automatically.| Kubernetes
Kubernetes reserves all labels, annotations and taints in the kubernetes.io and k8s.io namespaces. This document serves both as a reference to the values and as a coordination point for assigning values. Labels, annotations and taints used on API objects apf.kubernetes.io/autoupdate-spec Type: Annotation Example: apf.kubernetes.io/autoupdate-spec: "true" Used on: FlowSchema and PriorityLevelConfiguration Objects If this annotation is set to true on a FlowSchema or PriorityLevelConfiguration, ...| Kubernetes
This document highlights and consolidates configuration best practices that are introduced throughout the user guide, Getting Started documentation, and examples. This is a living document. If you think of something that is not on this list but might be useful to others, please don't hesitate to file an issue or submit a PR. General Configuration Tips When defining configurations, specify the latest stable API version. Configuration files should be stored in version control before being pushe...| Kubernetes
This guide is for application owners who want to build highly available applications, and thus need to understand what types of disruptions can happen to Pods. It is also for cluster administrators who want to perform automated cluster actions, like upgrading and autoscaling clusters. Voluntary and involuntary disruptions Pods do not disappear until someone (a person or a controller) destroys them, or there is an unavoidable hardware or system software error.| Kubernetes
Labels are key/value pairs that are attached to objects such as Pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects. Labels can be attached to objects at creation time and subsequently added and modified at any time.| Kubernetes
A DaemonSet defines Pods that provide node-local facilities. These might be fundamental to the operation of your cluster, such as a networking helper tool, or be part of an add-on.| Kubernetes
This page contains an overview of the various feature gates an administrator can specify on different Kubernetes components. See feature stages for an explanation of the stages for a feature. Overview Feature gates are a set of key=value pairs that describe Kubernetes features. You can turn these features on or off using the --feature-gates command line flag on each Kubernetes component. Each Kubernetes component lets you enable or disable a set of feature gates that are relevant to that comp...| Kubernetes
)
+ / / tl;dr - I did another round of drive testing (originally I only tested OpenEBS and hostPath), this time with some rented Hetzner machines and Ansible-powered automation. The GitLab repository isn’t ready for mass consumption yet but I’ll update here (and this tl;dr) when it is, along with the results. UPDATE (04/09/2020) The GitLab repository is up! You can skip this entire article and just go there. NOTE: This a multi-part blog-post!| vadosware.io
)
+ / / tl;dr - I explain the YAML and Makefile scripts that power the fio and pgbench (oltpbench) tests I’m going to run. UPDATE (04/10/2021) Turns out I was mistaken -- OpenEBS Mayastor doesn't support single-node disk-level failure domains. It's very well described on their website in the FAQ, but I somehow missed and/or forgot that, so the tests for Mayastor will only represent JBOD setup (no replication). On a different but related note, cStor supports cross disk replication (mirroring o...| vadosware.io
)
+ + UPDATE (10/28/2021) I've gotten some great feedback from a post in r/kubernetes and another post in r/zfs. I've added a section with some thoughts tl;dr - I recently switched my baremetal cluster storage setup to OpenEBS ZFS LocalPV + Longhorn. Some issues with Longhorn not running on PVCs aside, the setup is flexible perf wise (ZFS LocalPV) and I at least have a low-complexity option for distributed/HA storage (Longhorn).| vadosware.io
