If you’ve worked on a data team, you’ve likely encountered situations where multiple teams define metrics in slightly different ways, leaving you to untangle why discrepancies exist. The root cause of these metric deviations often stems from rapid data utilization without prioritizing long-term maintainability. Imagine this common scenario: a company hires its first data professional, who writes an ad-hoc SQL query to compute a metric. Over time, multiple teams build their own datasets us...| www.startdataengineering.com
System design interviews are usually vague and depend on you (as the interviewee) to guide the interviewer. If you are thinking: How do I prepare for data engineering system design interviews? I struggle to think of questions you would ask in a system design interview for data engineering; I don't have enough interview experience to know what companies ask. Is data engineering "system design" more than choosing between technologies like Spark and Airflow? This post is for you! Imagine being a...| www.startdataengineering.com
You want to democratize your company's data to a larger part of your organization. However, trying to teach SQL to nontechnical stakeholders has not gone well. Stakeholders will always choose the easiest way to get what they want: by writing bad queries or opening an ad-hoc request for a data engineer to handle. You hope stakeholders will recognize the power of SQL, but it can be disappointing and frustrating to know that most people do not care about learning SQL but only about getting what ...| www.startdataengineering.com
Efficient Data Processing in SQLA guide to understanding the core concepts of distributed data storage & processing, analytical functions, and query optimizations in your data warehouse.You want to be able to write efficient data processing pipelines in SQL, but you don't know where to start!There are too many topics to learn to get proficient at efficient data processing in SQL, like optimizing queries, partitioning, parallelism, data modeling, best practices, etc. It is overwhelming to have...| Gumroad
Whether you are a new Data Engineer or someone with a few years of experience, you inevitably would have encountered messy data systems that seemed impossible to fix. Working at such a company usually comes with multiple pointless meetings, no clear work expectations, frustration, career stagnation, and ultimately no satisfaction from work! The reasons can be Managerial: Such as politics, red tape, cluelessness of management, influential people dictating roadmap, etc or Technical: Such as no ...| www.startdataengineering.com
Data engineering project for beginners, using AWS Redshift, Apache Spark in AWS EMR, Postgres and orchestrated by Apache Airflow.| www.startdataengineering.com
Struggling to come up with a data engineering project idea? Overwhelmed by all the setup necessary to start building a data engineering project? Don't know where to get data for your side project? Then this post is for you. We will go over the key components, and help you understand what you need to design and build your data projects. We will do this using a sample end-to-end data engineering project.| www.startdataengineering.com
Are you disappointed with online SQL tutorials that aren't deep enough? Are you frustrated knowing that you are missing SQL skills, but can't quite put your finger on it? This post is for you. In this post, we go over a few topics that can take your SQL skills to the next level and help you be a better data engineer.| www.startdataengineering.com
Unclear data engineering job description ? Wondering what responsibilities falls within a data team ? Then this post is for you. In this post we go over the 6 key responsibilities of a data engineer. The number of these responsibilities that you may end up handling depends on your company and team. Teams in smaller companies generally handle all 6 responsibilities, whereas larger sized companies may have individual(or multiple) teams handling one(or a mix) of these responsibilities.| www.startdataengineering.com
In this post, we go over 6 key concepts to help you master window functions. Window functions are one the most powerful features of SQL, they are very useful in analytics and performing operations that cannot be done easily with the standard group by, subquery and filters. Despite this, window functions are not used frequently. If you have ever thought 'window functions are confusing', then this post is for you.| www.startdataengineering.com
This post goes over what the ETL and ELT data pipeline paradigms are. It tries to address the inconsistency in naming conventions and how to understand what they really mean. Finally ends with a comparison of the 2 paradigms and how to use these concepts to build efficient and scalable data pipelines.| www.startdataengineering.com
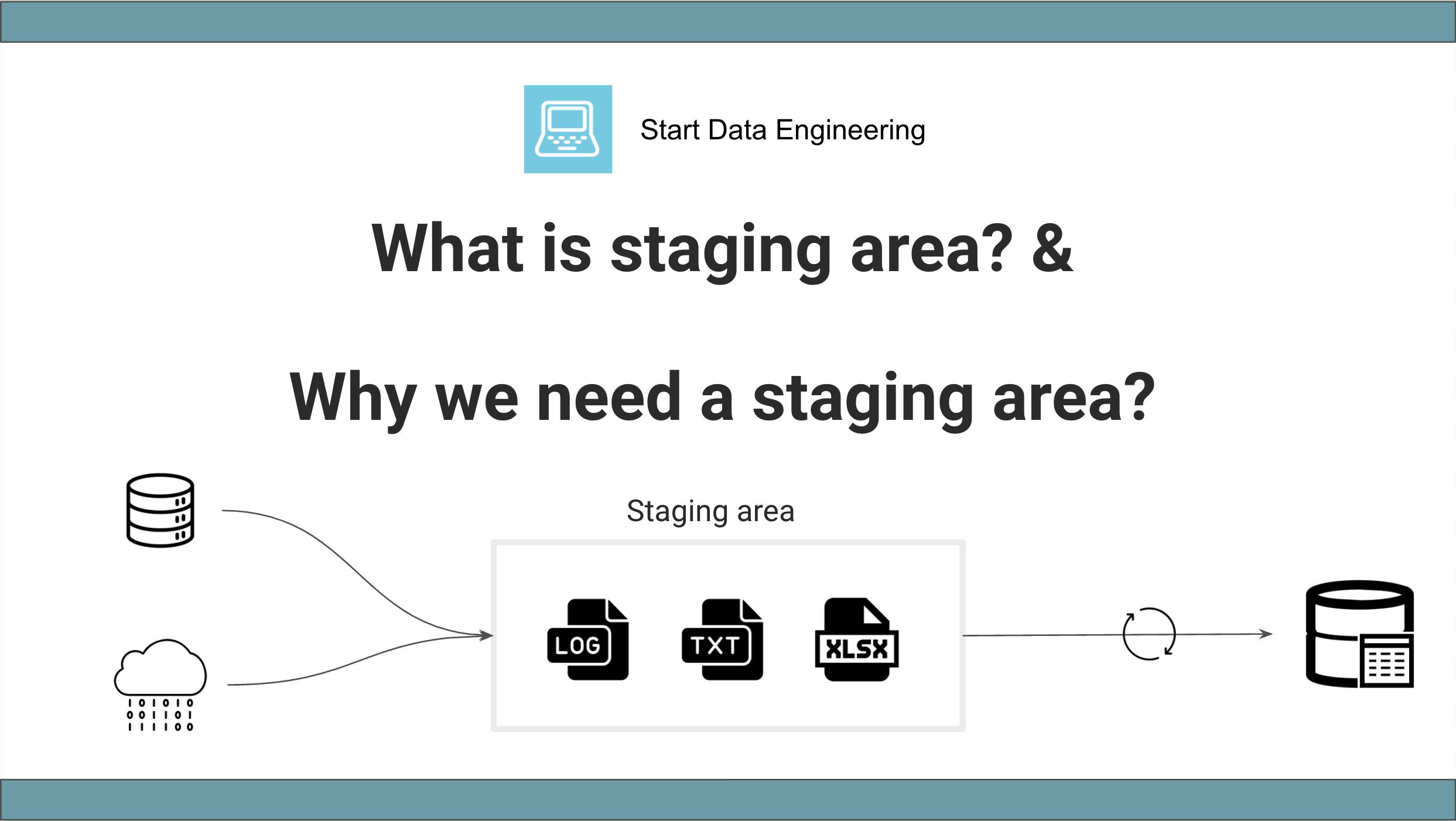
Wondering what is staging and why you need one for your data pipelines? Then this post is for you. In this post, we will go over what exactly a staging area is and why it is crucial for data pipelines.| www.startdataengineering.com
If you are overwhelmed with re-engineering a legacy data pipeline, then this post is for you. In this post, we go over 6 key principles to help you figure out the most impactful data features for your end user and how to deliver them.| www.startdataengineering.com
Setting up an ELT data-ops workflow with multiple environments for developers is often extremely time consuming. What if there was a way to speed up this process, so that you could concentrate on modeling your data and delivering value to your end users? The good news is that there is a way. You can leverage dbt cloud to setup an ELT data-ops workflow in a very short time. In this post, we cover how to setup a data-ops workflow for an ELT system. We will go over how to setup dbt, snowflake, C...| www.startdataengineering.com
Wondering how to store a dimension table's history over time and how to join these historical dimension tables with fact tables for analytical querying ? Then this post is for you. In this post, we will go over a popular dimension modeling technique called SCD2, which preserves historical changes. We will also see how to join a fact table with an SCD2 table to get accurate point in time information.| www.startdataengineering.com
Data pipelines built (and added on to) without a solid foundation will suffer from poor efficiency, slow development speed, long times to triage production issues, and hard testability. What if your data pipelines are elegant and enable you to deliver features quickly? An easy-to-maintain and extendable data pipeline significantly increase developer morale, stakeholder trust, and the business bottom line! Using the correct design pattern will increase feature delivery speed and developer valu...| www.startdataengineering.com