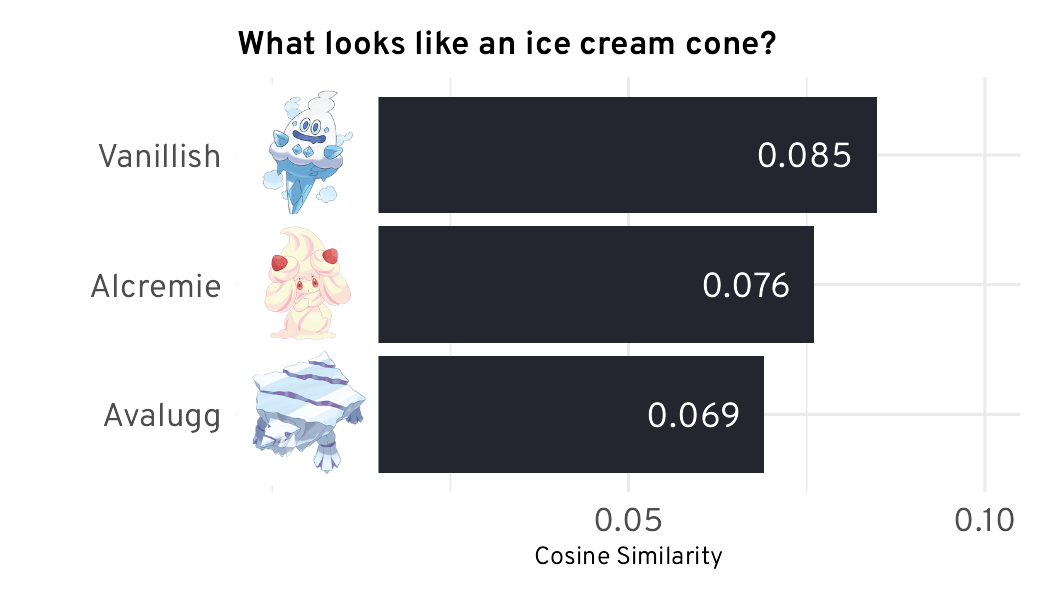
The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images | Max Woolf's Blog
Embeddings encourage engineers to go full YOLO because it’s actually rewarding to do so!| minimaxir.com
Introduction| Neel Nanda
在之前的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中我们提出了旋转式位置编码RoPE以及对应的Transformer模型RoFormer。由于笔者主要研究的领域还是NL...| spaces.ac.cn
fleetwood.dev| fleetwood.dev
Embeddings encourage engineers to go full YOLO because it’s actually rewarding to do so!| minimaxir.com
Here’s a fact: GPT-4o charges 170 tokens to process each 512x512 tile used in high-res mode. At ~0.75 tokens/word, this suggests a picture is worth about 227 words—only a factor of four off from the traditional saying. (There’s also an 85 tokens charge for a low-res ‘master thumbnail’ of each picture and higher resolution images are broken into many such 512x512 tiles, but let’s just focus on a single high-res tile.| www.oranlooney.com

Scaling Llama3 beyond 1M context window with ~perfect utilization, the difference between ALiBi and RoPE, how to use GPT-4 to create synthetic data for your context extension finetunes, and more!| www.latent.space
Ever since its introduction in the 2017 paper, Attention is All You Need, the Transformer model architecture has taken the deep-learning world by storm. Initially introduced for machine translation, it has become the tool of choice for a wide range of domains, including text, audio, video, and others. Transformers have also driven most of the massive increases in model scale and capability in the last few years. OpenAI’s GPT-3 and Codex models are Transformers, as are DeepMind’s Gopher mo...| Made of Bugs

What we've been up to for the past year EleutherAI.| EleutherAI Blog
