
What is Apache Spark? The big data platform that crushed Hadoop | InfoWorld
Fast, flexible, and developer-friendly, Apache Spark is the leading platform for large-scale SQL, batch processing, stream processing, and machine learning.| InfoWorld
Fast, flexible, and developer-friendly, Apache Spark is the leading platform for large-scale SQL, batch processing, stream processing, and machine learning.| InfoWorld
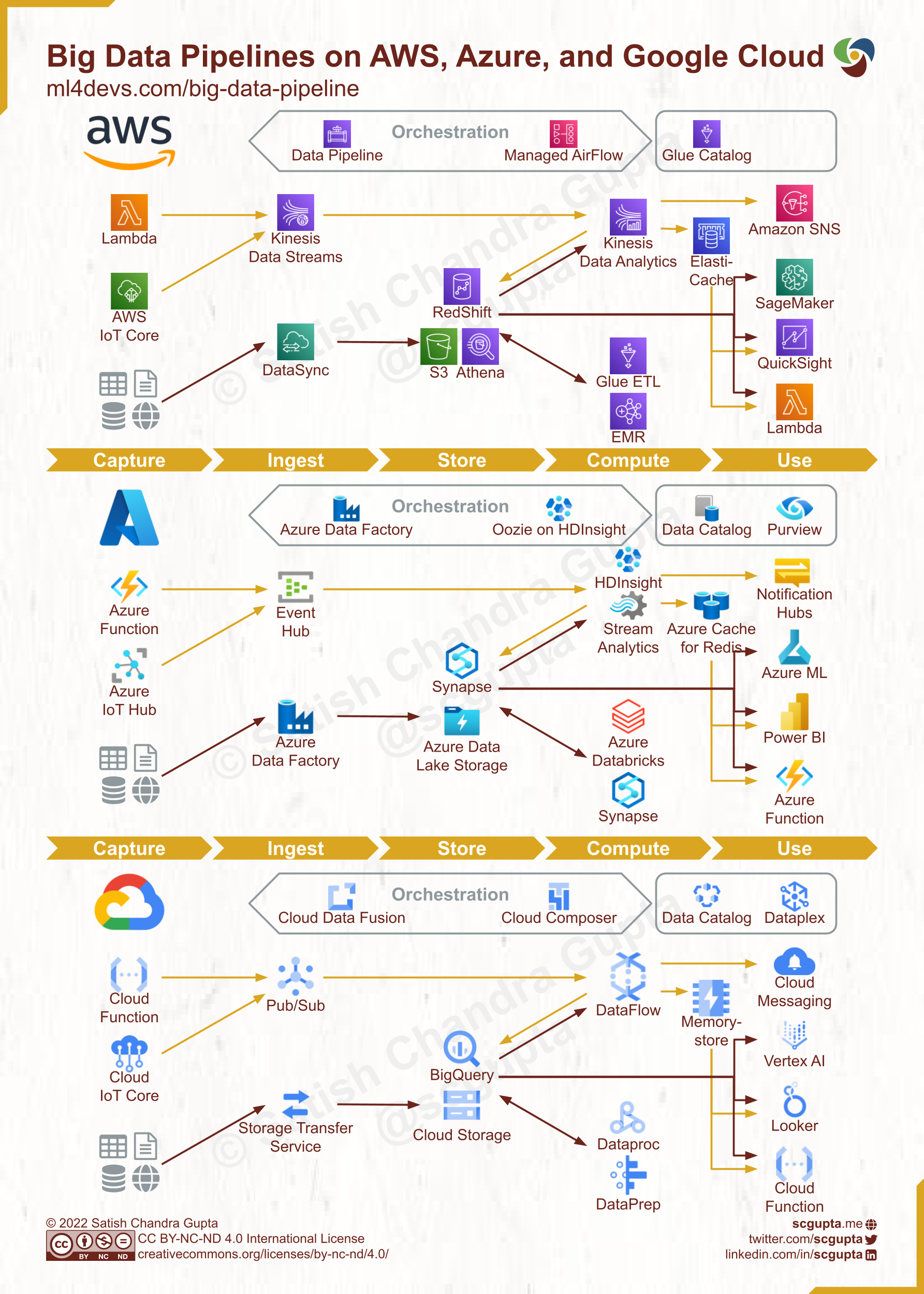
Scalable and efficient data pipelines are as important for the success of data science and machine learning as reliable supply lines are for winning a war.| Machine Learning for Developers

In Theo’s previous posts on storing high momentum data and its accompanying metadata we get some interesting insights into the future of cloud based data storage.| jacobtomlinson.dev
