Building RAG-based LLM Applications for Production
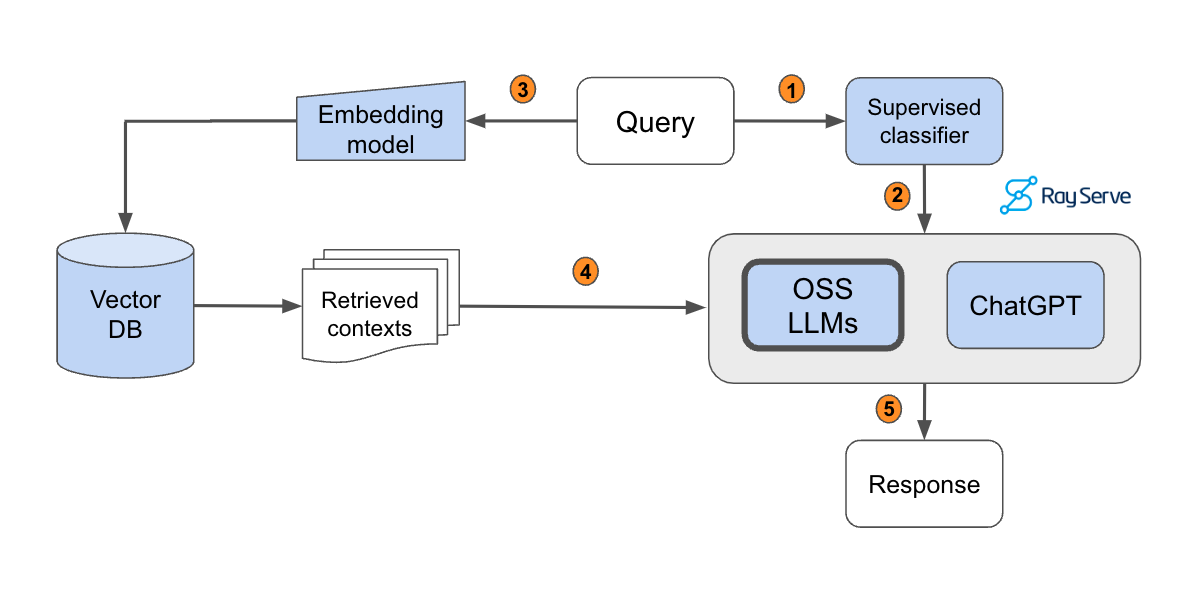
In this guide, we will learn how to develop and productionize a retrieval augmented generation (RAG) based LLM application, with a focus on scale and evaluation.| Anyscale
from typing import Dict| docs.ray.io
In this guide, we will learn how to develop and productionize a retrieval augmented generation (RAG) based LLM application, with a focus on scale and evaluation.| Anyscale

In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.| Anyscale
