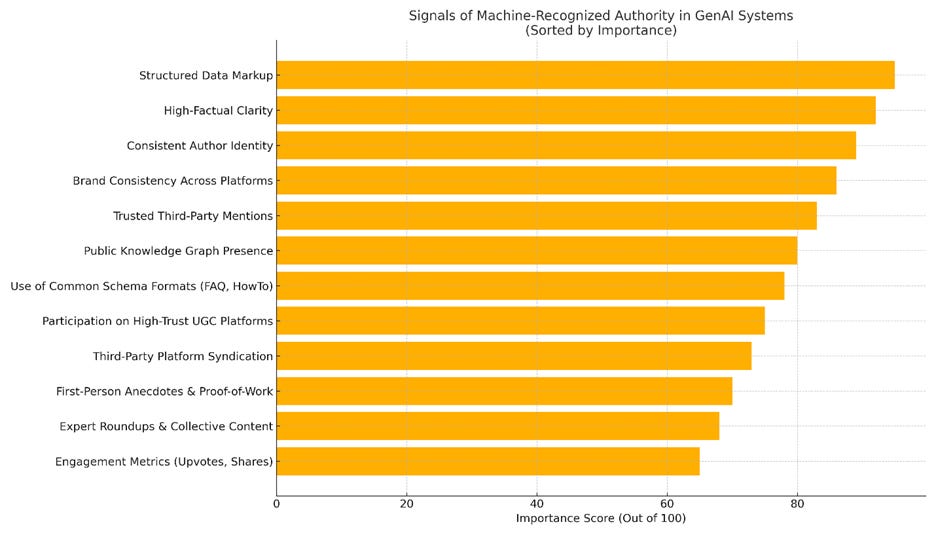
Machine Trust: Authority, Rebuilt for Retrieval
Tactics for Visibility and Trust in AI-Driven Discovery| duaneforresterdecodes.substack.com
Tactics for Visibility and Trust in AI-Driven Discovery| duaneforresterdecodes.substack.com

Discover how Schema App's Entity Hub solution helps enterprise teams measure Entity SEO performance and prove ROI.| Schema App Solutions

Entity Hub helps marketing teams build a clear, connected understanding of their content so they can optimize for AI search. Learn more.| Schema App Solutions

Could they be the secret to higher rankings?| SEO Blog by Ahrefs
Semantic search is a central concept in natural language AI systems. Learn about all the ways it works and the tools that support it.| www.timescale.com
Some months ago, I saw a job posting for Wikibase.Cloud’s product manager.| antonin.delpeuch.eu

The Cleveland Museum of Art is proud to be an open access institution, offering the public the ability to download, share, collaborate, remix, and reuse images and metadata of public-domain artworks from the museum’s collection.| www.clevelandart.org
A few days ago I wanted to find a dataset with a list of winners of the Palme d’Or. The table on Wikipedia wasn’t formatted in a way that would be easy to copy, and I figured this was as good a time as any to figure out how Wikidata works.| notes.rolandcrosby.com
Automatische Erzeugung von POI-Karten aus Offenen Daten 2022-10-27, 02:00 de en Open Data Wikidata OpenStreetMap Die Website des Chaos Computer Clubs enthält eine Karte von Deutschland und den umliegenden Ländern, auf der Hackerspaces verzeichnet sind, die sich als Teil des CCC betrachten. Bisher…| s3lph.me
Justin Barrett, Lead Machine Learning Engineer for OpenAlex at OurResearch, talks with ROR Technical Community Manager Amanda French and ROR Curation Lead Adam Buttrick about using ROR in OpenAlex both as an identifier for institutions and as a dataset for training machine learning models.| Research Organization Registry (ROR)
Extracting metadata from our documents is an important part of our discovery and recommendation pipeline, but discerning useful and relevant details from text-heavy user-uploaded documents can be challenging. This is part 2 in a series of blog posts describing a multi-component machine learning system the Applied Research team built to extract metadata from our documents in order to enrich downstream discovery models. In this post, we present the challenges and limitations the team faced when...| Scribd Technology

Supported by all major search engines, the Schema.org vocabulary helps search engines to better understand and contextualize web content.| Schema App Solutions

What is ontology? An ontology is a formal system for modeling concepts and their relationships. Unlike relational database systems, which are essentially interconnected tables, ontologies put a premium on the relationships between concepts by storing the information in a graph database, or triplestore. (The following examples use data derived from PLOS, which makes all of its Open Access data and content available.) Relational databases are good at representing tabular data for one-to-one rel...| Boxes and Arrows
Wikidata can be a useful resource for journalists digging for data on a deadline. Here is a guide to using the community-edited database as a data source.| DataJournalism.com

Inspired by the endless quandaries we see with structured data, here we discuss how to plan and implement schema, all while avoiding common mistakes.| thegray.company
