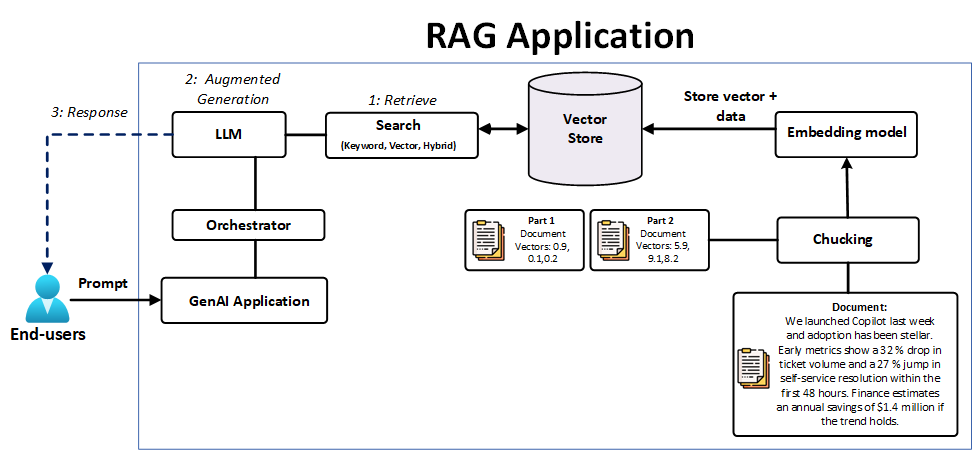
Learn about Vector Search in TiDB. This feature provides an advanced search solution for performing semantic similarity searches across various data types, including documents, images, audio, and video.| docs.pingcap.com
The title is a bit misleading, but the main focus is on GenAI applications and services with your data. If you want to build a GenAI service that you want to connect with your data, RAG has so far been the preferred approach. However that does not mean that it is going to be perfect … How to make data “AI-ready”? Read More »| msandbu.org
Authors: Lara Rachidi & Maria Zervou Introduction Welcome to our technical blog on the challenges encountered when building and deploying Retrieval-Augmented Generation (RAG) applications. RAG is a GenAI technique used to incorporate relevant data as context to a large language model (LLM) without t...| community.databricks.com
Building proper search requires selecting the right embedding model for your specific use case. This guide helps you navigate the selection process based on performance, cost, and other practical considerations.| qdrant.tech
AI Mode is transforming Google Search beyond recognition, and SEO isn’t ready. This article explains how generative search works, why traditional tactics are falling short, and what marketers must do to adapt.| iPullRank
DeepSeek R1 has shown great reasoning capability when it is firstly released. In this blog post, we detail our learnings in using DeepSeek R1 to build a Retrieval-Augmented Generation (RAG) system, tailored for legal documents. We choose legal documents because legal professionals often face a daunting task: navigating libraries of cases, statutes, and informal legal commentary. Even the best-intentioned research can get bogged down in retrieving the right documents, let alone summarizing the...| SkyPilot Blog
When directly compared with OpenAI's 8K model text-embedding-ada-002, the jina-embeddings-v2 stand out in terms of quality. Their long context length is a game changer. Don't let a missing model implementation stop you from realizing your awesome AI project in Elixir. Instead, follow three steps to convert a Python model to Elixir.| bitcrowd.dev
Read time: 10 minutes Nearly all modern coding assistants and agents leverage some form of code retrieval — the task of retrieving relevant code snippets, docstrings, or documentation, etc., from c…| Voyage AI
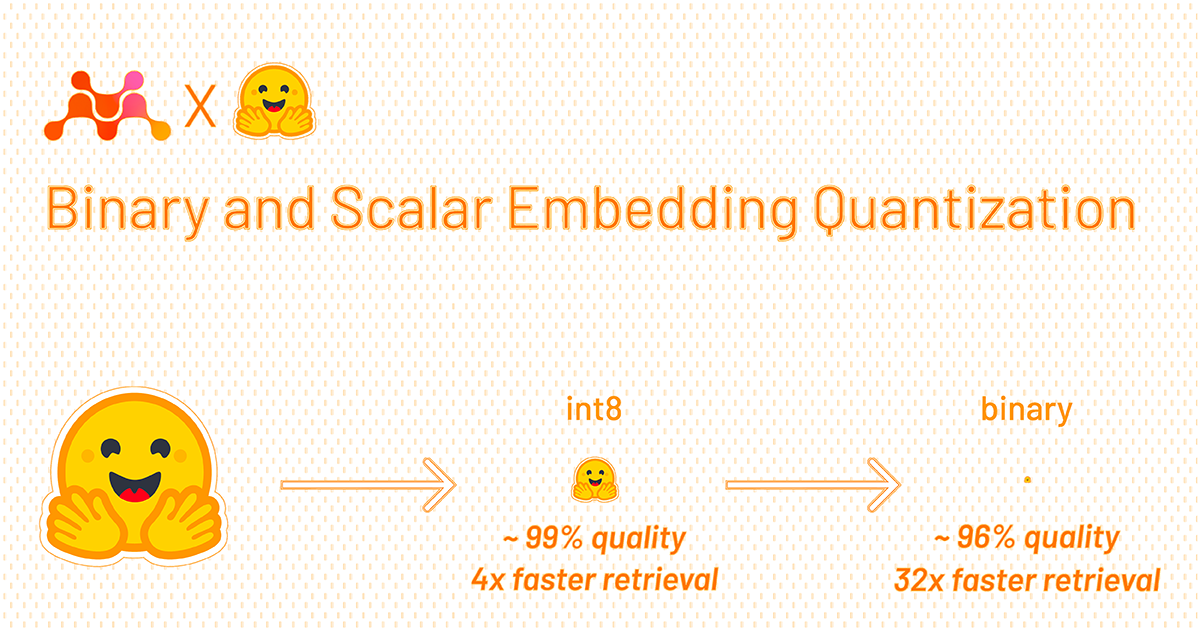
Vector embeddings by themselves are pretty neat. Binary quantized vector embeddings are extra impressive. In short, they can retain 95+% retrieval accuracy with 32x compression 🤯.| Evan Schwartz
Model Choices Voyage currently provides the following text embedding models: Model Context Length (tokens) Embedding Dimension Description voyage-3-large 32,000 1024 (default), 256, 512, 2048 The best general-purpose and multilingual retrieval quality. See blog post for details. voyage-3 32,000 1024...| Voyage AI
Update 2024-05-14: Hot off the presses, the benchmark now includes the recently released GPT-4o model! How good are LLMs at trivia? I used the Jeopardy! dataset from Kaggle to benchmark ChatGPT and the new Llama 3 models. Here are the results: There you go. You’ve already gotten 90% of what you’re going to get out of this article. Some guy on the internet ran a half-baked benchmark on a handful of LLM models, and the results were largely in line with popular benchmarks and received wisdom...| www.oranlooney.com
Learn the SEO use cases when you leverage Screaming Frog's new feature to run bespoke JS functions and generate vector embeddings from OpenAI.| iPullRank
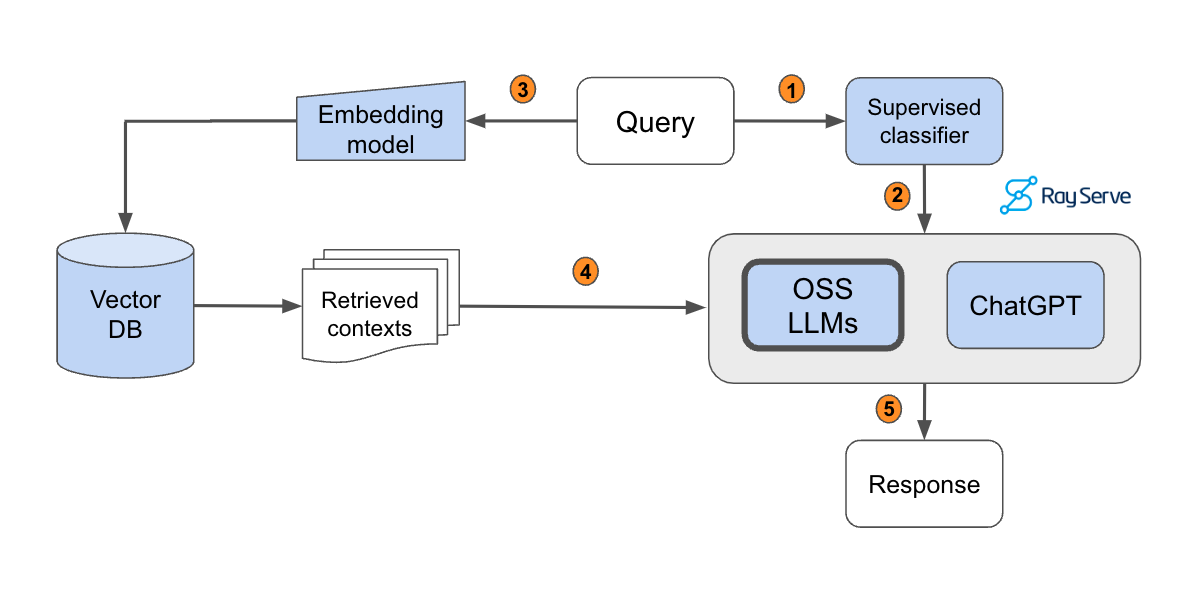
In this guide, we will learn how to develop and productionize a retrieval augmented generation (RAG) based LLM application, with a focus on scale and evaluation.| Anyscale
How can the 2012 Nobel Prize in Economics, Vector Search, and the world of dating come together? What are the implications for the future of databases? And why do Multi-Modal AI model evaluation datasets often fall short? Synopsis: Stable Marriages are generally computed from preference lists. Those consume too much memory. Instead, one can dynamically recalculate candidate lists using a scalable Vector Search engine. However, achieving this depends on having high-quality representations in a...| ashvardanian.com